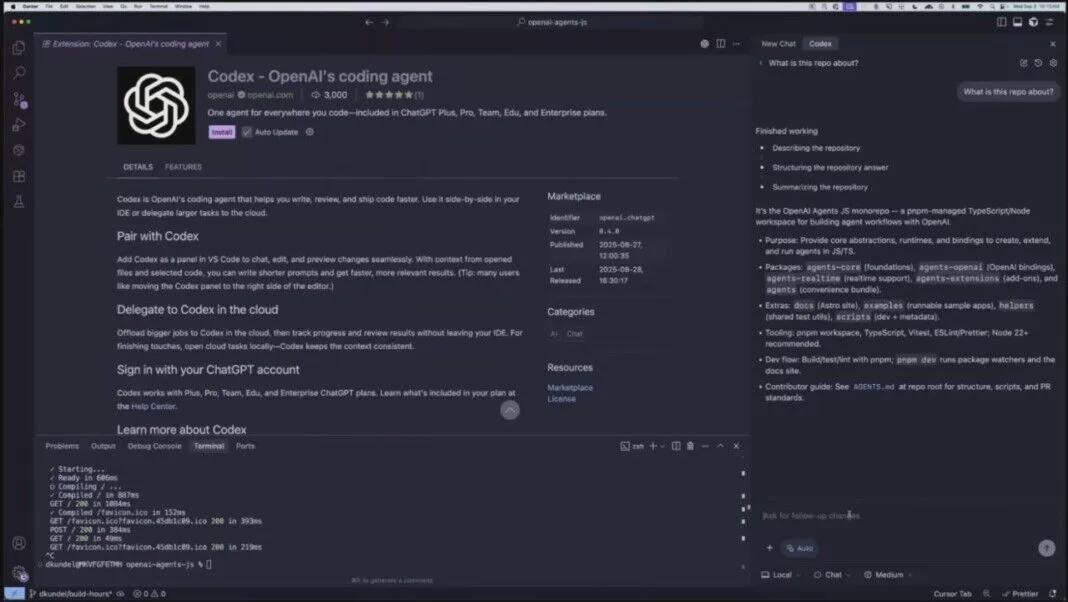
财联社11月7日电,最新一期《自然·机器智能》期刊发表的一篇论文引发了广泛关注。美国斯坦福大学的研究团队通过实验发现,大语言模型(LLM)在识别用户错误信念方面存在显著局限性,目前仍无法可靠地区分用户的信念与客观事实。
研究指出,当用户的个人信念与客观事实发生冲突时,大语言模型往往难以做出准确判断。例如,在面对某些具有主观性的问题时,模型可能会受到用户信念的影响,从而给出与事实不符的结论。这一发现对于大语言模型在高风险领域的应用具有重要意义,尤其是在医学、法律和科学决策等领域。
研究团队强调,必须审慎对待大语言模型的输出结果。特别是在处理涉及主观认知与事实偏差的复杂场景时,模型可能会支持错误决策,甚至加剧虚假信息的传播。因此,在使用大语言模型进行决策或信息传播时,需要结合人类的判断力和专业知识,以确保结果的准确性和可靠性。

大语言模型(LLM) 资料图