谷歌发布迄今最强大AI模型Gemini 3:重新定义多模态智能边界
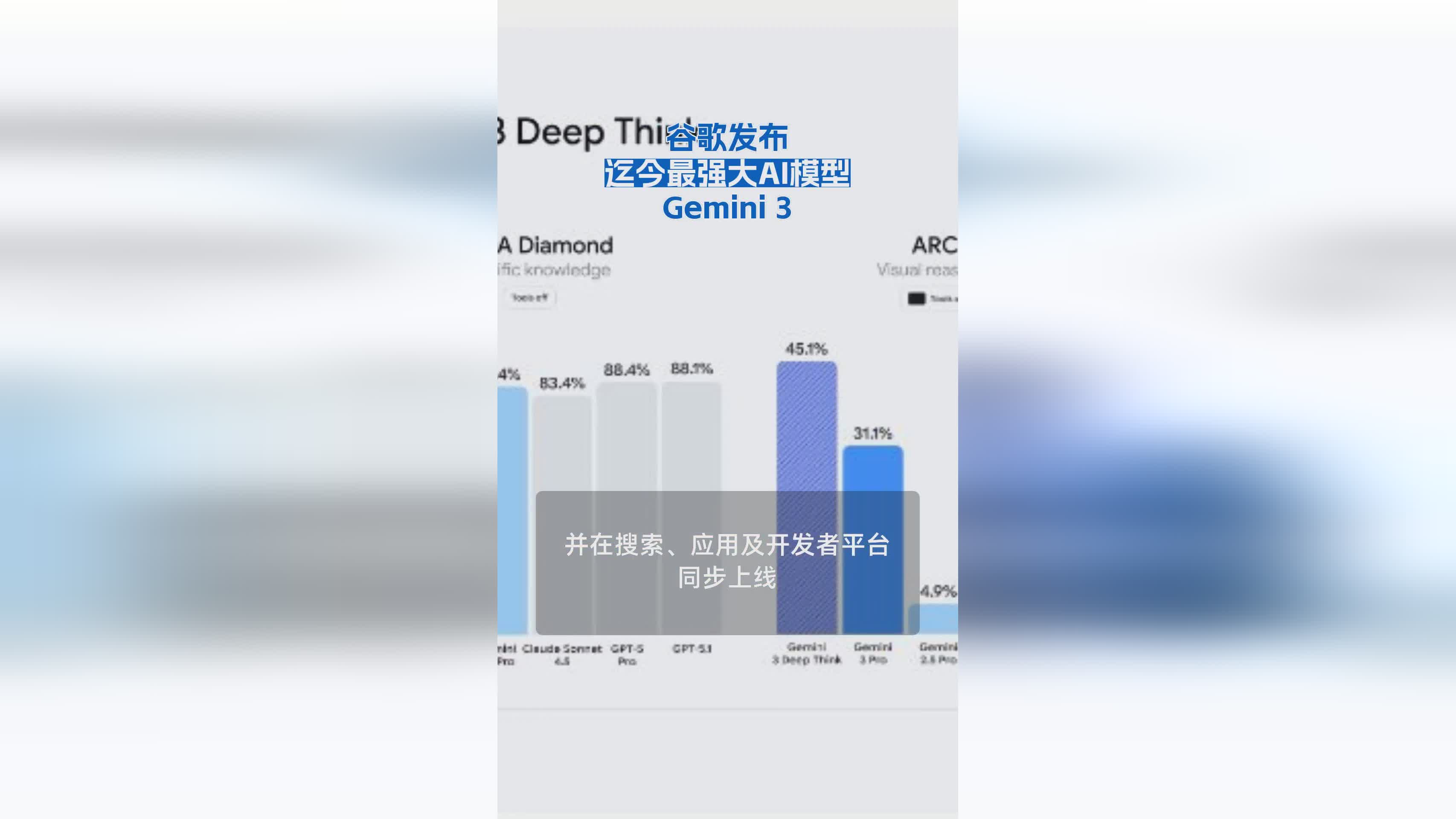
全球科技巨头谷歌近日正式推出新一代AI模型Gemini 3,凭借其突破性的多模态处理能力与跨领域适应性,迅速成为人工智能领域的焦点。该模型不仅在文本、图像、视频理解等基础任务上表现卓越,更在复杂推理、实时交互等场景中展现出显著优势,标志着AI技术向通用化迈出关键一步。
技术亮点:多模态融合与跨场景适应
Gemini 3的核心突破在于其原生支持多模态输入输出,能够无缝处理文本、图像、音频及视频数据。例如,在医疗诊断场景中,模型可同时分析患者病历文本、X光影像及语音描述,生成综合诊断建议;在教育领域,它能根据学生手写笔记、课堂录音及实验视频动态调整教学方案。这种跨模态理解能力,使其在复杂任务处理上远超前代模型。
性能提升:效率与精度的双重飞跃
据谷歌官方披露,Gemini 3在MMLU(大规模多任务语言理解)基准测试中得分较前代提升23%,在视频内容理解任务中准确率突破91%。其训练架构采用动态注意力机制,可根据任务复杂度自动调整计算资源分配,在保持高精度的同时,将推理速度提升40%。这一特性使其在移动端设备及边缘计算场景中具备更强的实用性。
应用场景:从科研到日常的全面覆盖
目前,Gemini 3已开放开发者预览版,支持通过API接入。首批应用案例包括:
行业影响:重塑AI开发范式
分析人士指出,Gemini 3的发布将推动AI应用从单一模态向复合场景迁移。其开放的模块化设计允许开发者根据需求定制功能,降低技术门槛的同时,为垂直领域创新提供更多可能。谷歌AI负责人表示:“我们正致力于构建一个‘无感知’的AI生态,让技术自然融入人类工作流,而非强制用户适应机器逻辑。”
视频演示:直观感受Gemini 3的强大能力
(注:以上视频为官方演示片段,展示Gemini 3在实时翻译、场景识别及多轮对话中的表现)