当地时间11月18日,Alphabet旗下谷歌(Google)正式推出新一代大型语言模型Gemini 3,并宣布即日起将其部署至谷歌搜索的AI模式、Gemini应用、API接口及VertexAI等核心产品。这一动作被业界视为谷歌在生成式AI领域的重要突破,官方更将其定义为“通往AGI(通用人工智能)的重要一步”,强调其多模态理解能力与交互深度已达到全球领先水平。
Alphabet首席执行官桑达尔·皮查伊(Sundar Pichai)在公司官方博客中表示,Gemini 3是“目前最先进、最智能的推理模型”,其设计目标不仅是提升技术性能,更要帮助用户以更自然的方式探索世界。根据公开数据,Gemini系列应用月活跃用户已突破6.5亿,AI Overviews功能覆盖超20亿用户,显示出强大的市场渗透力。
从现场演示来看,Gemini 3的核心优势在于其多模态整合能力。该模型可无缝处理文本、图像、视频、音频及代码等任意组合的信息形式,并通过先进的推理引擎、视觉理解与空间感知技术,实现跨模态深度交互。例如,当用户学习新主题时,Gemini 3不仅能提供学术论文、视频讲座等传统资源,还能生成交互式记忆卡片、可视化代码或动态模拟工具,支持个性化学习路径。
在信息呈现方式上,Gemini 3颠覆了传统搜索引擎的链接列表模式,转而采用沉浸式视觉布局与交互式工具。例如,用户查询旅行攻略时,模型可即时生成包含日程规划、预算分配及交通方案的动态界面,甚至预测潜在问题并提供解决方案。
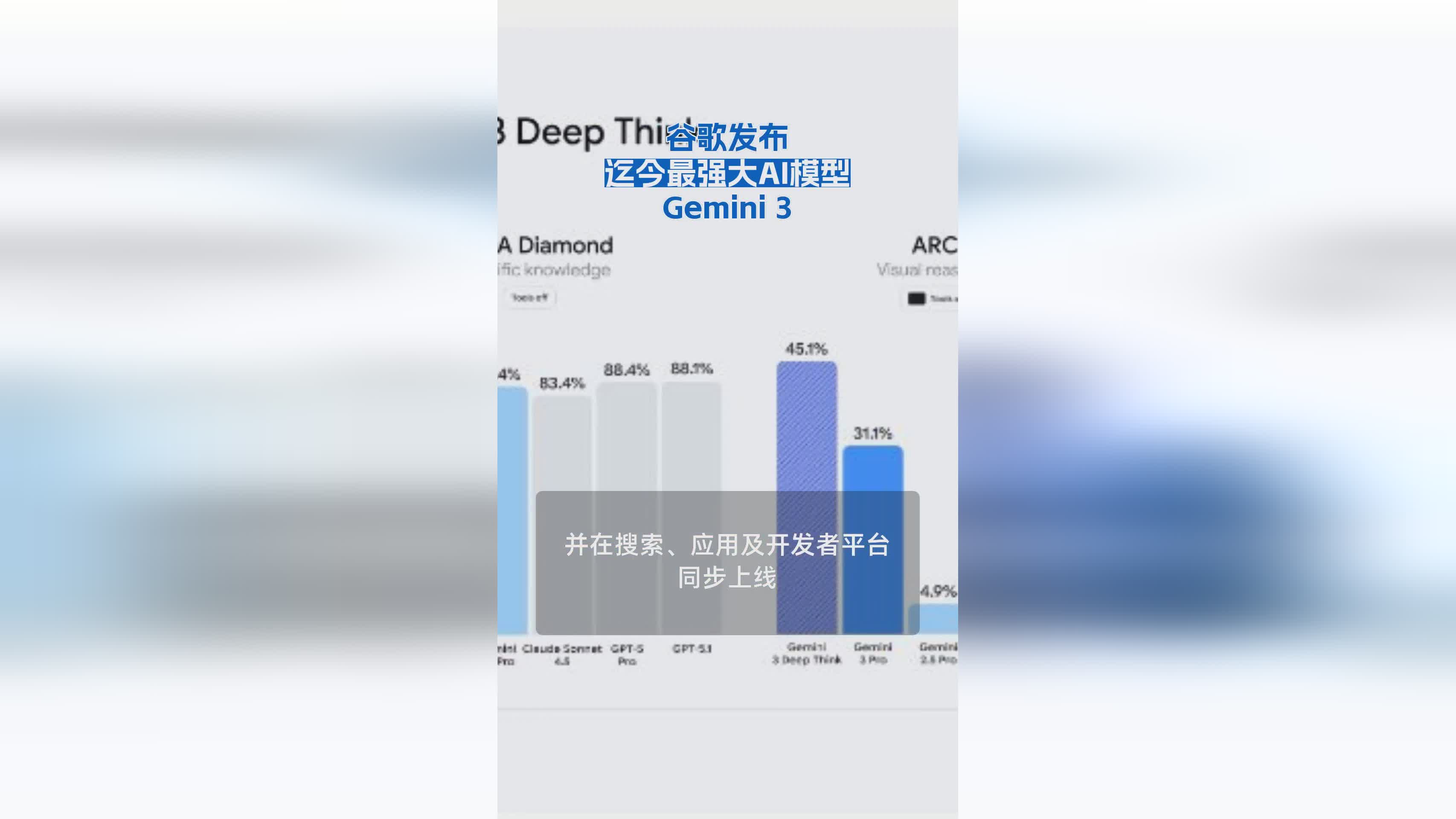
第三方评测平台数据显示,Gemini 3在推理任务中以显著优势领先通用模型竞争者。其多模态理解能力尤为突出:在一个测试场景中,模型需解析一本手写符号混杂、排版混乱的笔记本,不仅能精准识别内容,还能自动消解符号歧义,最终输出堪比专业学生的答案。这种跨图像、跨学科、跨语境的推理链条,标志着AI从“答题机器”向“理解世界运作机制”的进化。
此外,Gemini 3展现出对动态环境的强大适应力。它可读懂界面变化、预测用户操作,甚至通过分析视频帧推断物理环境中的物体运动规律。例如,在模拟实验中,模型能根据少量视觉线索预测台球碰撞轨迹,其准确率接近人类专家水平。
现场演示中,Gemini Agent展示了多项实用功能:
Gemini 3现已全面开放使用:普通用户可通过Gemini App及搜索AI模式体验基础功能,订阅用户与企业客户则能通过AI Studio、Vertex AI等渠道接入高级版本。定价方面,Gemini 3.0 Pro采用基于上下文长度的分级机制:200k tokens以下任务的输入/输出价格为2.00美元/12.00美元(每百万token),超过200k tokens则升至4.00美元/18.00美元。
桑达尔·皮查伊在博客中披露,目前已有超70%的谷歌云客户及1300万开发者使用其生成式模型,形成覆盖全球的AI生态。随着Gemini 3的推出,谷歌进一步巩固了在多模态AI领域的领导地位,也为通用人工智能的商业化落地提供了新范式。