就在刚刚,人工智能领域迎来重要进展——DeepSeek正式发布实验性模型DeepSeek-V3.2-Exp。这款被官方定义为“迈向新一代架构的中间步骤”的模型,在技术架构与商业化层面均实现突破性升级。
据官方技术文档披露,V3.2-Exp在V3.1-Terminus版本基础上,首次引入DeepSeek Sparse Attention稀疏注意力机制。该机制通过动态优化注意力权重分配,显著提升长文本场景下的训练与推理效率,为处理超长文本任务(如法律文书分析、科研论文解析等)提供更高效的解决方案。
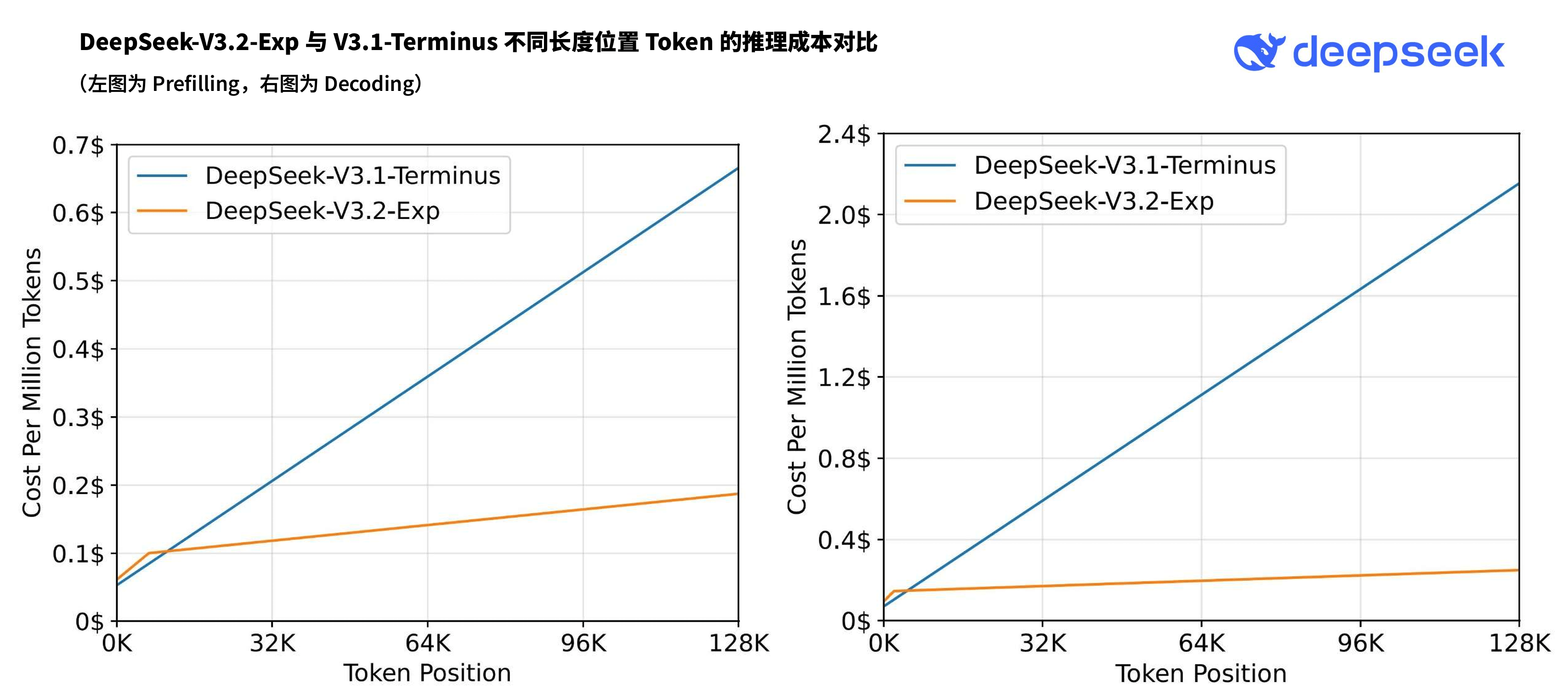
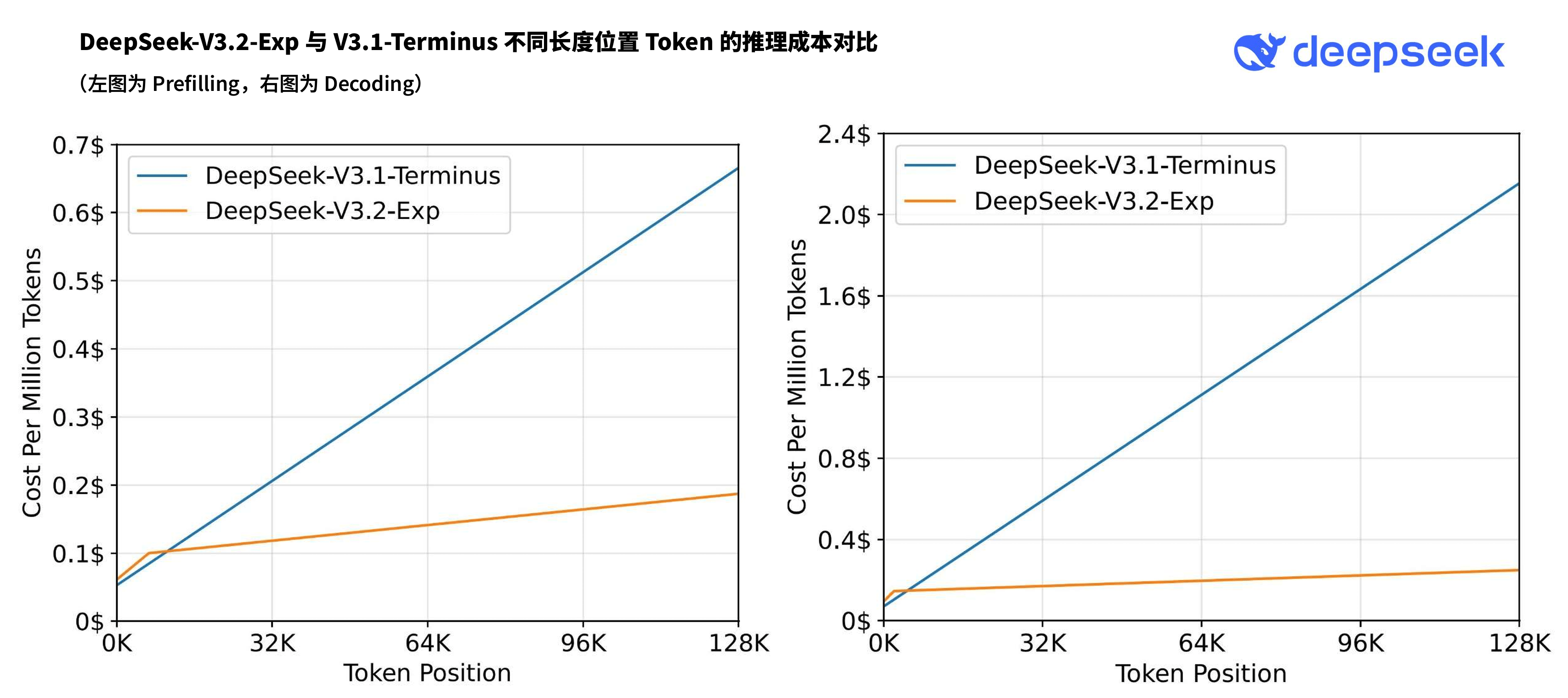
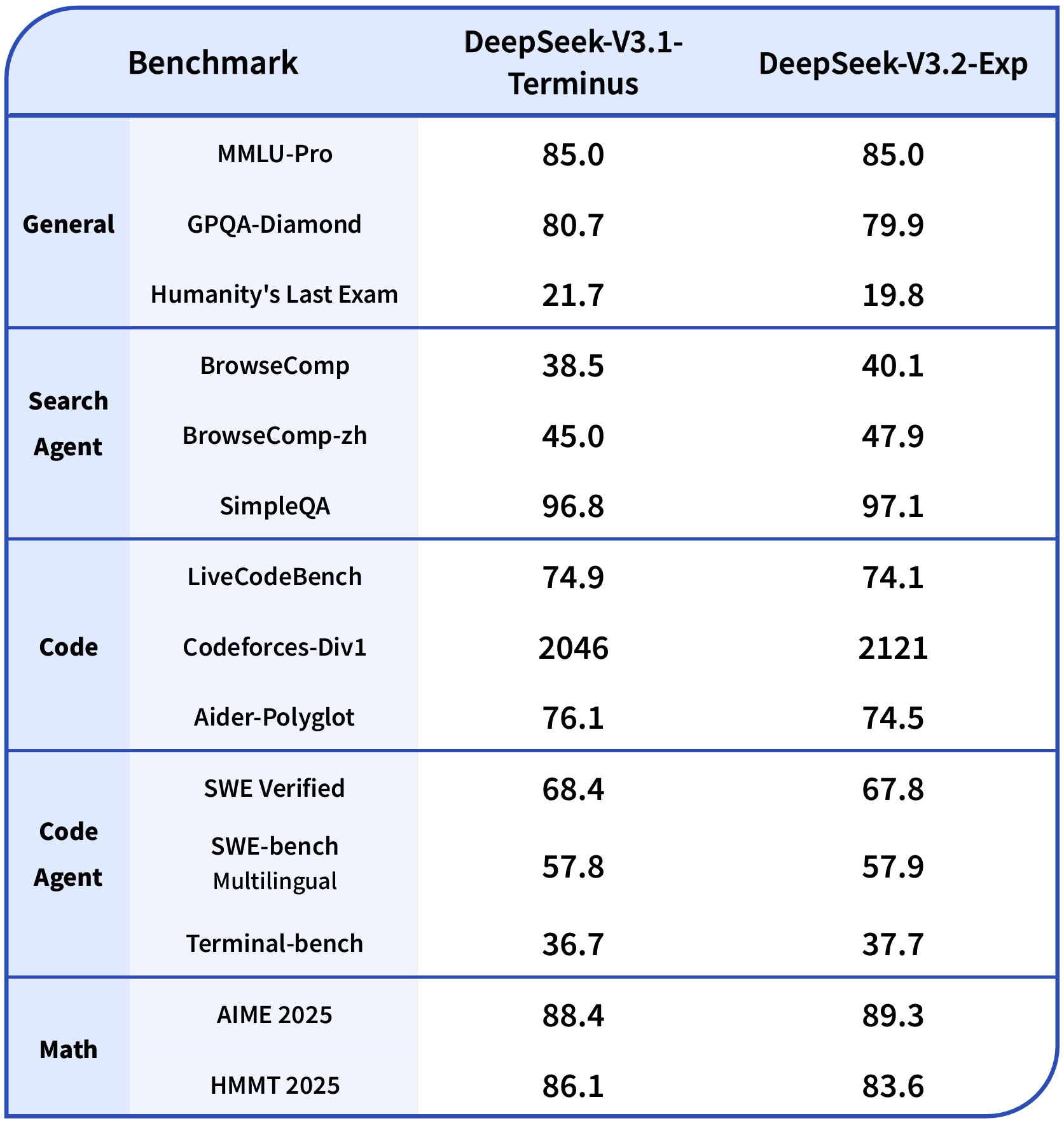
性能测试数据显示,V3.2-Exp在公开评测集上的表现与前代V3.1-Terminus基本持平,但在成本效率维度实现质的飞跃。通过稀疏注意力机制的应用,模型单次推理的算力消耗降低约40%,这为API价格的大幅下调奠定技术基础。
最受开发者关注的API价格体系迎来重大调整。受益于新架构的效率提升,DeepSeek宣布将API调用价格下调50%以上,新价格已即时生效。此举将显著降低企业级用户的AI应用成本,尤其在需要高频调用的场景中(如智能客服、内容生成等),成本优势将进一步凸显。

在生态建设方面,V3.2-Exp已同步更新至DeepSeek官方App、网页端与小程序,并在HuggingFace和魔搭平台开源。开发者可自由获取模型权重、训练代码及技术论文。更值得关注的是,DeepSeek首次开放TileLang编程语言与CUDA优化版GPU算子,为社区研究者提供深度定制化的开发工具,加速技术迭代进程。
作为实验性版本,DeepSeek特别邀请全球开发者在实际业务场景中进行更大规模的测试验证。为方便性能对比,公司决定临时保留V3.1-Terminus的API接口,该通道将开放至2025年10月15日,为新旧模型切换提供平稳过渡期。
本文数据来源于DeepSeek官方公告,更多技术细节与行业动态,请持续关注科技媒体报道。