智东西
作者 陈骏达
编辑 李水青
昨晚,AI领域迎来历史性时刻——DeepSeek团队再次创造突破!由梁文锋担任通讯作者的DeepSeek-R1推理模型研究论文,正式登上国际顶级学术期刊《自然(Nature)》封面,标志着中国AI科研成果首次以完整同行评审形式获得国际权威认可。
全球首个主流大模型通过Nature同行评审
据智东西9月18日报道,这篇发表于9月17日的论文首次揭示了仅通过强化学习(RL)即可激发大模型推理能力的核心技术。该成果不仅启发全球AI研究者重新思考模型训练范式,更以超过1090万次的Hugging Face下载量成为全球最受欢迎的开源推理模型。
《自然》杂志在社论中特别指出:在主流大模型普遍缺乏独立验证的背景下,DeepSeek-R1成为全球首个通过完整同行评审的主流语言模型,填补了AI科研领域的关键空白。期刊评价该研究是"迈向技术透明度和可重复性的重要一步",尤其在行业充斥未经证实宣传的当下更具示范意义。

封面论文揭示技术突破细节
相比1月发布的初版技术报告,此次《自然》版论文新增大量关键信息:
论文披露的64页同行评审文件显示,8位国际专家对模型原创性、训练方法及鲁棒性进行严格评估,提出上百条修改建议,包括数据透明度、术语准确性等细节。这种开放态度获得《自然》高度评价:"通过主动接受独立审查,DeepSeek为行业树立了科研诚信的标杆。"

技术突破:强化学习驱动模型进化
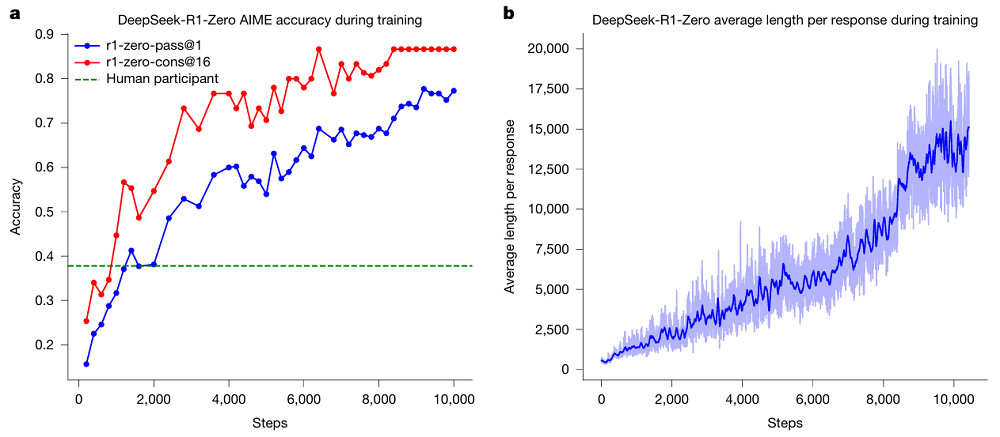
研究核心揭示了AI推理能力训练的范式转变。传统方法依赖人工标注思维链轨迹,而DeepSeek-R1通过GRPO强化学习框架,仅用最终预测结果与真实答案的匹配度作为奖励信号,使模型自主发展出包含验证、反思和备选方案探索的复杂推理策略。
实验数据显示,随着推理长度增加,DeepSeek-R1-Zero的答题正确率显著提升,回答中验证步骤占比达68%,反思行为出现频率比基线模型高42%。这种自我改进能力使模型在数学、编程等复杂任务中表现突出,同时通过多阶段训练结合RL、拒绝采样和监督微调,最终版本在保持强推理能力的同时更符合人类偏好。
行业影响:推动科研透明化进程
《自然》杂志特别强调该研究的示范价值:在AI技术加速普及的背景下,厂商未经证实的宣传可能带来社会风险,而独立同行评审是抑制过度炒作的有效手段。期刊呼吁更多机构效仿DeepSeek的开源模式,通过提交模型接受第三方验证,提升技术可信度。
作为中国AI开源生态的代表,DeepSeek-R1此次不仅提供核心论文,更同步公开同行评审报告、补充材料及安全评估文档,为全球研究者提供完整的模型复现路径。这种全方位开放策略,使其Hugging Face下载量持续领跑开源社区,更被《自然》视为"构建负责任AI生态的重要实践"。
研究资源链接
结语:开源模式引领行业新标准
此次DeepSeek-R1登上《自然》封面,不仅是中国AI技术实力的证明,更预示着全球科研评价体系向透明化转型的趋势。通过完整披露训练细节、主动接受同行评审、持续更新安全机制,DeepSeek团队为行业树立了可复制的科研范式。随着《自然》呼吁更多机构跟进,这场由中国团队发起的透明化运动,或将重新定义AI技术的可信度标准。