新智元报道
编辑:桃子
【新智元导读】离职Meta后,田渊栋团队最新论文放出了。他们提出的「三门理论」发现,RLVR微调只在小权重里发力,性能提升的同时又不破坏模型结构。
田渊栋离职Meta之后,最后一篇亲笔?
上月末,Meta血裁600人团队,AI大佬田渊栋官宣自己也被裁员。
最近,他在Meta期间一篇论文正式发布,已被顶会NeurIPS 2025录用。
最新研究中,他们发现一个反常却稳定的规律——
强化学习与可验证奖励(RLVR)虽能提升模型性能,但几乎不碰主方向上的权重。
这是一种受模型结构自身约束的优化偏置。
这背后的原因究竟是什么,不如打开「黑箱」看一看。

论文地址:https://arxiv.org/pdf/2511.08567
论文中,团队提出了「三门理论」,即KL锚点 → 几何结构 → 精度。
它能解释并刻画AI独特的优化行为,也为近期一系列来自参数空间的观察现象,提供了可解释性:
其中就包括,RL更新稀疏、RL遗忘较少,在线量化秩序一次校准。
更重要的是,RLVR的优化方式与监督微调(SFT)完全不同,而且,人们常在SFT中用到的方法,不一定在RL中好使。

总言之,新论文最大的贡献在于,首次绘制出RLVR训练动态的「参数层面全景图」。
RL学习,优化偏差从哪来?
在研究之前,Meta团队提出了一个关于RL学习动态的核心问题:
优化偏差是从哪里产生的?它在训练过程中如何影响参数的变化?

为此,他们专门探索了RLVR方法。
它是通过使用确定性的、可验证的奖励函数,去提高LLM在精确任务中的性能。
RLVR会在同一个预训练模型的前提下,把更新引导到跨不同运行、数据集和训练方案中的同一类偏好区域。这是一种受模型本身影响的优化偏向。
如下所示,在训练过程中,RL会把更新集中在同一模型的相同区域。
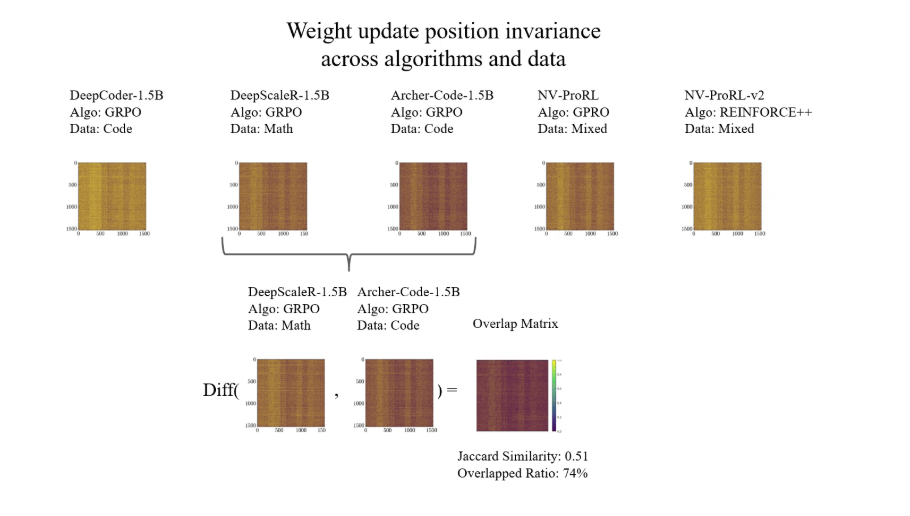
每个面板展示的是一个0-1更新掩码(1=已更改,0= 更改)。尽管使用的数据和算法不同,这种条纹状模式仍在不同运行中反复出现
1 RL会将更新定位到同一模型的相同区域
这里,作者分析了DeepSeek-R1-Distill-Qwen-1.5B的5次微调运行。
这些运行分别使用了,包括数学、代码等多样化数据,以及不同的RL变体,如GRPO、DAPO、Reinforcement++。
首先计算更新掩码 M_i,通过比较基础模型和微调模型来追踪更新集中在哪些位置。
随后,更新一致性比率:
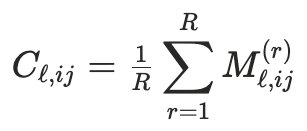
如下所示,在五次RLVR运行中,团队绘制了第13层的投影(Q/K/V/O)以及MLP的下投影。
较亮的条带标记了在大多数运行中被更新的坐标,呈现出一种稳定的、类似条纹的路由模式,而不是随机散布。
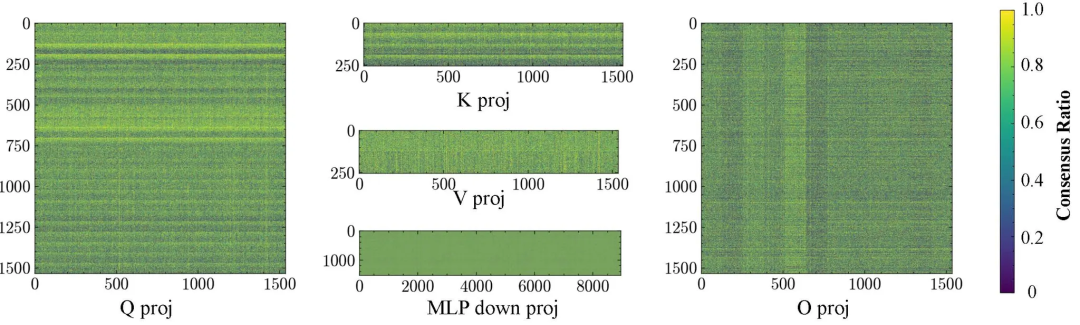
权重更新的一致性比例
2 优化偏向在整个训练过程中持续存在
为了研究单次运行内部的动态变化,作者又在DeepSeek-R1-Distill-Qwen-1.5上,跟踪了训练步骤中的按行和按列的更新比率:
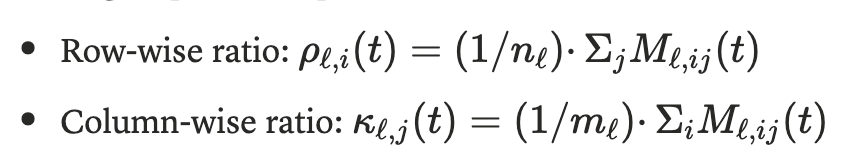
下图中,路由偏向在训练初期便开始出现,并在训练推进中不断增强。
这表明这是一种随时间保持稳定的现象,而不是短暂的偶发现象。 其峰值与图2中的偏置结构一致。
3 这种偏向可在不同模型族之间泛化
不仅如此,作者又在Llama和Mistral上,同样观察到了类似的条纹结构特征。
这表明,这种路由偏向是RLVR的普遍现象。
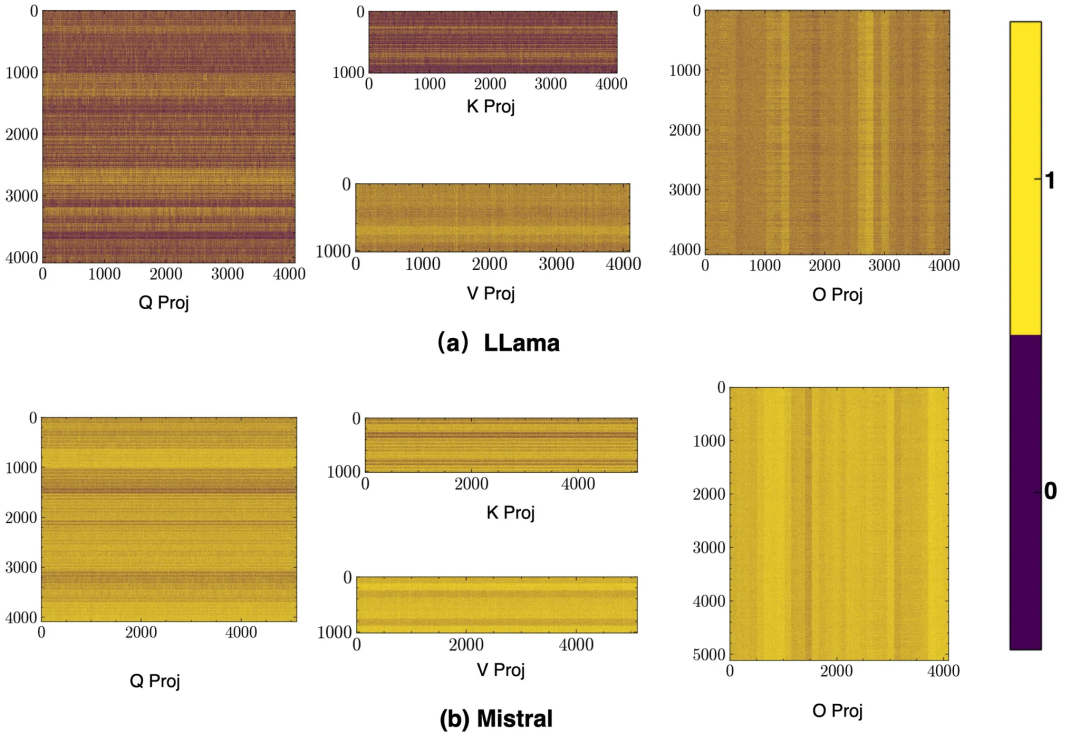
「三门」理论,破解黑盒
那么,究竟是什么驱动了RLVR独特的训练动态?
论文中,研究人员提出了一个「三门理论」。具体来说,每一步RL更新都会经过三个「门」——
它们共同将更新从主方向偏离,并引导进入低曲率、保持谱结构的区域。
门一: KL锚点对更新的约束
实验显示,同策略(on-policy) 的RL更新,会施加一种隐式的KL「牵引绳」,即锚点效应。
这使得每一步策略的偏移都保持很小。
巧的是,这一观察与近期MIT、斯坦福等机构研究的观点一致。此前研究表明,最终策略也与初始策略保持KL上的接近。


接下来的重点在于,这条「牵引绳」是如何影响权重更新的动态过程?
门二:模型几何结构决定KL约束下更新的落点
上面的门一,提供了限制单步偏移的KL「牵引绳」,但并不规定更新会落在哪里。
在一个预训练良好、具有结构化几何特性的模型中,小幅更新会局限在其既有几何结构内。
根据矩阵扰动理论,如Wedin的sin-Θ定理),小范数扰动只会导致极小的子空间旋转,并保持近乎稳定的谱结构。
在KL约束下,RL更新往往会保持模型的原始权重结构,而不是将其破坏。
因此,更新会自然偏向优化地形的低曲率方向,从而避免模型行为出现剧烈变化。
鉴于直接在长CoT的LRM中量化曲率成本极高,团队又采用一种高效的替代指标——主权重(principal weight)。
门三:精度限制
正如作者所言,存不下的东西看起来就像「稀疏」的。
bf16的有限精度(仅有7位尾数)像一块「透镜」:它会掩盖那些RL想持续施加但幅度过小、无法被有效存储的微更新。
基于理论的验证:RLVR优化动态
在参数层面,作者验证了RLVR的学习动态,其与理论框架高度一致。
尤其是,门二所描述的「更新偏向非主权重」。RLVR在提升推理能力的同时避开主方向:
它保持谱几何结构、避开主权重;而一旦预训练的几何结构被破坏,这种优化偏向也会随之消失。
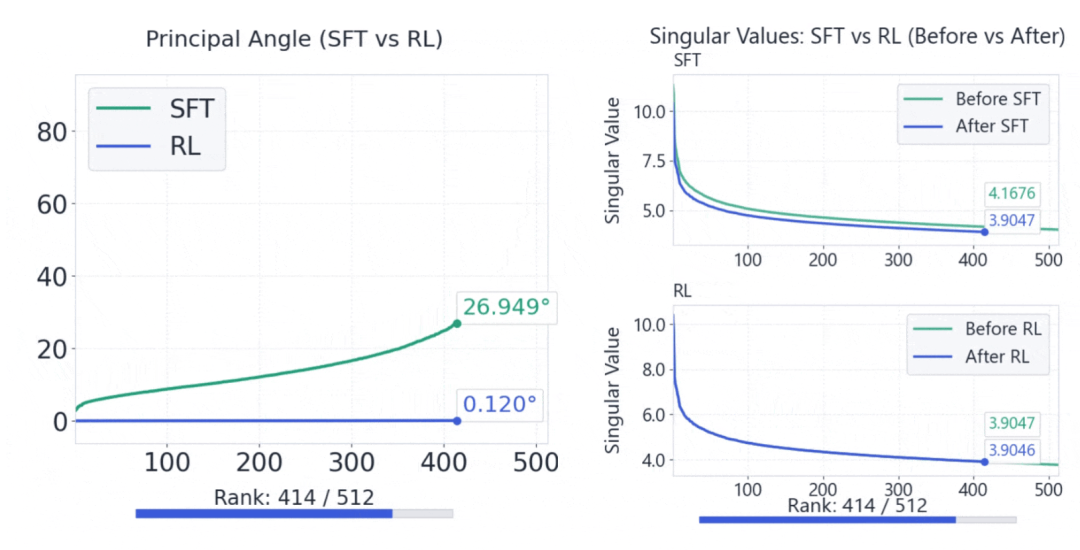
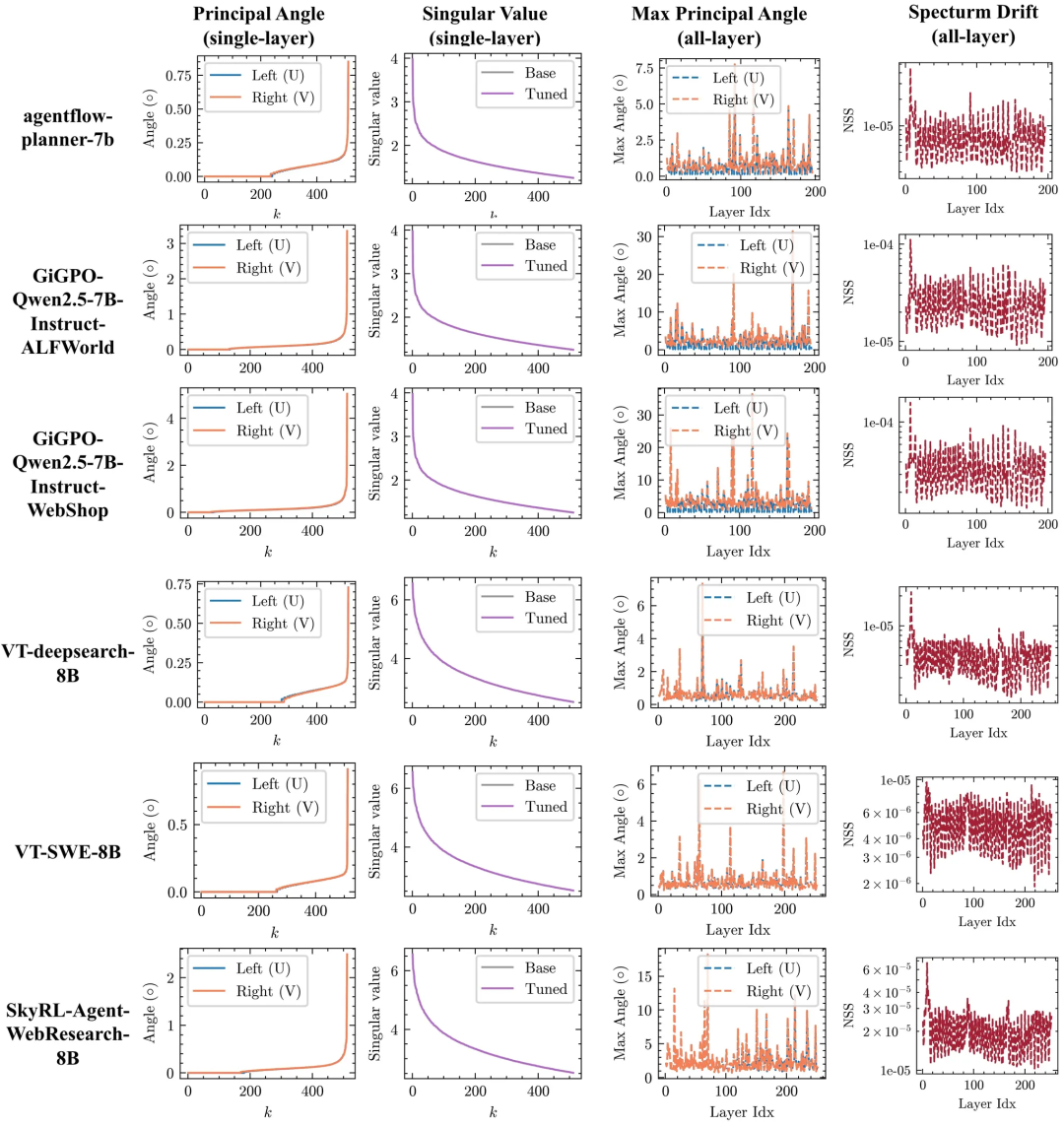
RLVR保持谱几何结构,而SFT会破坏它
如下所示,是SFT与RLVR在Qwen3-8B-Base上的谱几何对比。
与SFT相比,RLVR能保持稳定的前k阶谱,并显著减少子空间旋转。
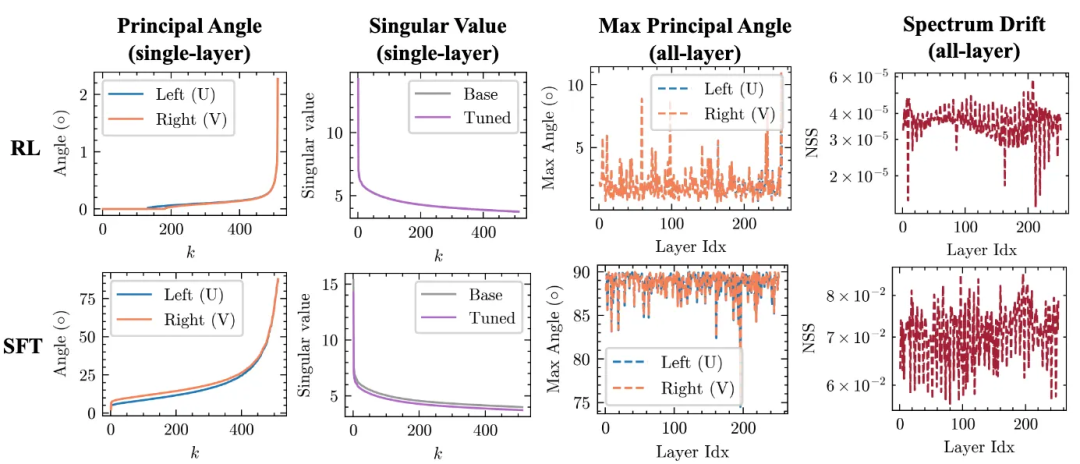
左图:示例层的前k个主角度和奇异值曲线;右图:跨所有层的最大主角度与归一化谱漂移
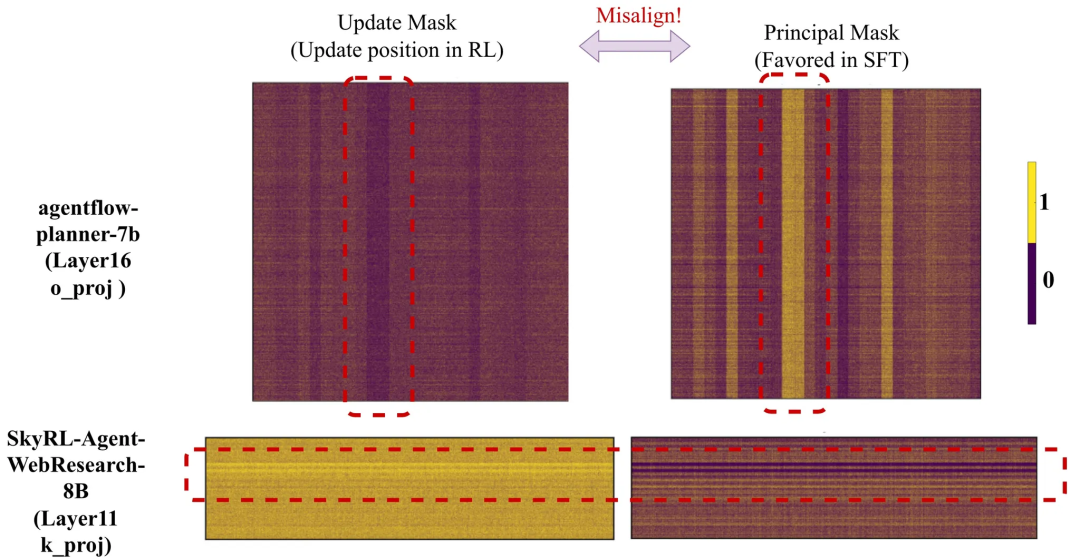
RLVR会避开主权重,而SFT则会直接更新主权重
下图中,RL会避免更新主权重。
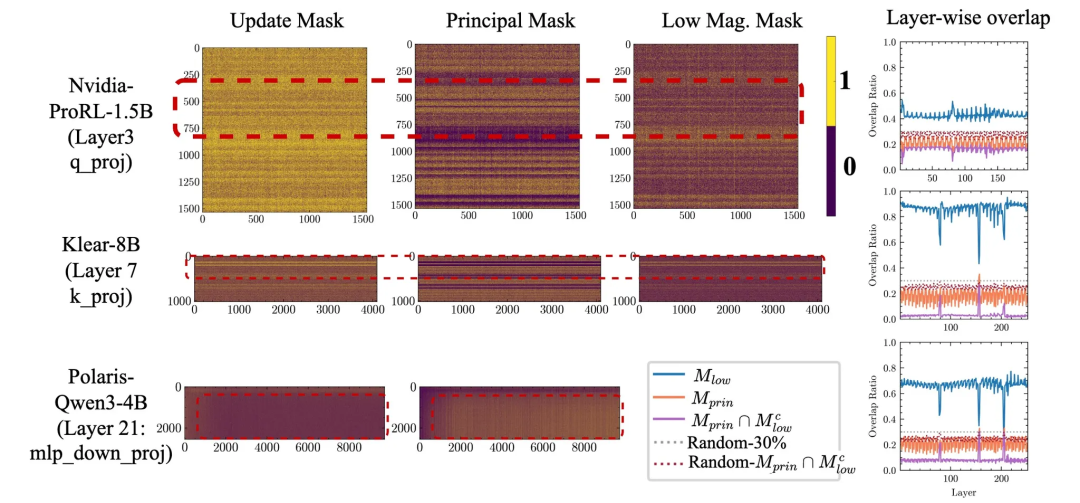
研究人员将RL的更新掩码与主权重掩码M_princ、低幅值掩码M_low,以及二者的组合M_princ ∩ M_low^c进行对比。
RL更新与主权重之间的逐层重叠比例始终低于随机水平;
而当去除其与M_low的重叠权重(即M_princ ∩ M_low^c)后,这种效应表现得更为明显。
RL算法重新思考
作者观察到的训练动态揭示了一个超越机制本身的重要洞见:
RL在参数空间中的优化机制,与SFT完全不同。
那些诞生于SFT时代的旧PEFT方法,尤其是依赖稀疏或低秩先验、并因此与SFT训练动态高度对齐的方法,在RLVR中的迁移表现并不好。
下图中的曲线直接验证了:SFT中偏好的主方向更新,对于RL并不有效。
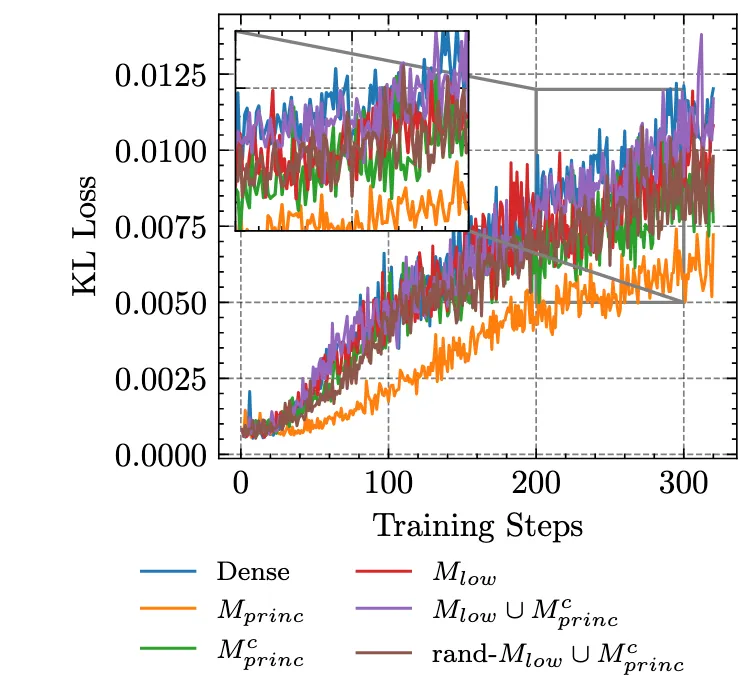
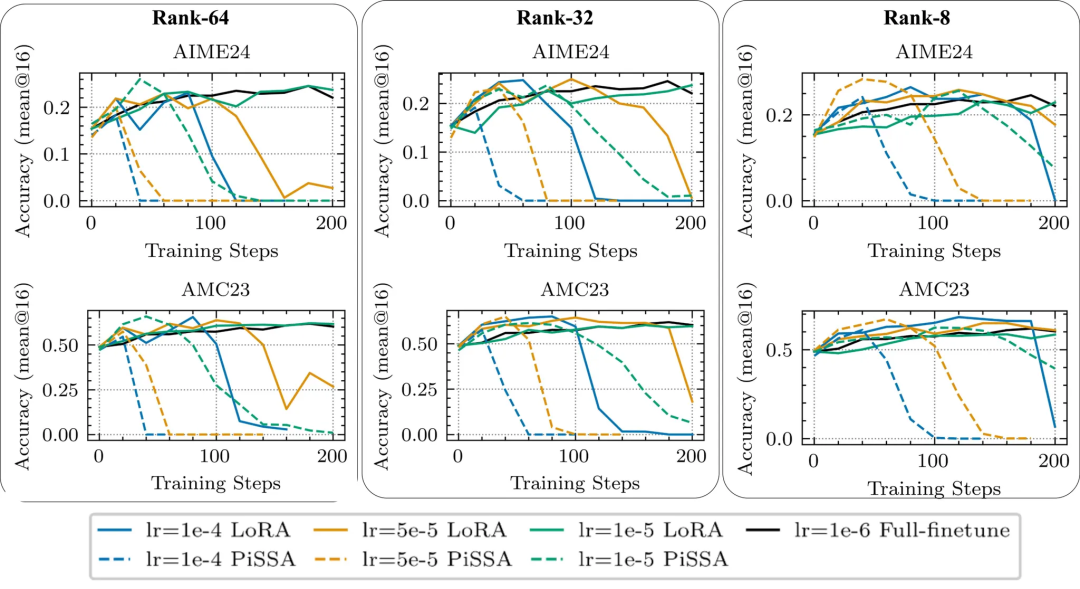
下图中,是LoRA与PiSSA在DS-Qwen-1.5B(DeepMath-103K)上的表现对比。
整体来看,PiSSA(以主方向为目标)相较LoRA并未带来额外收益;
并且在较高学习率、被强制推动主方向更新时,它往往会在早期崩溃,而LoRA依然更为稳定。
这一结果支持了研究中的几何分析:强行将更新推入SFT所偏好的主方向与RL的优化特性并不匹配,不但无法带来明显收益,还会在放大学习率时导致训练崩溃。
智能体与RLHF任务
此外,作者还分析了额外的智能体与RLHF(基于人类反馈的 RL)检查点,并确认它们在权重空间上的诊断结果与前文一致:
(i) 主子空间旋转幅度极小,
(ii) 谱漂移轻微,
(iii) 更新与主方向存在显著错位。
如下是更多关于关于智能体和RLHF的实验结果。
参考资料:
https://x.com/tydsh/status/1989049095575728156?s=20