2025.11.19

本文字数:1100,阅读时长约2分钟
作者 |第一财经 钱童心
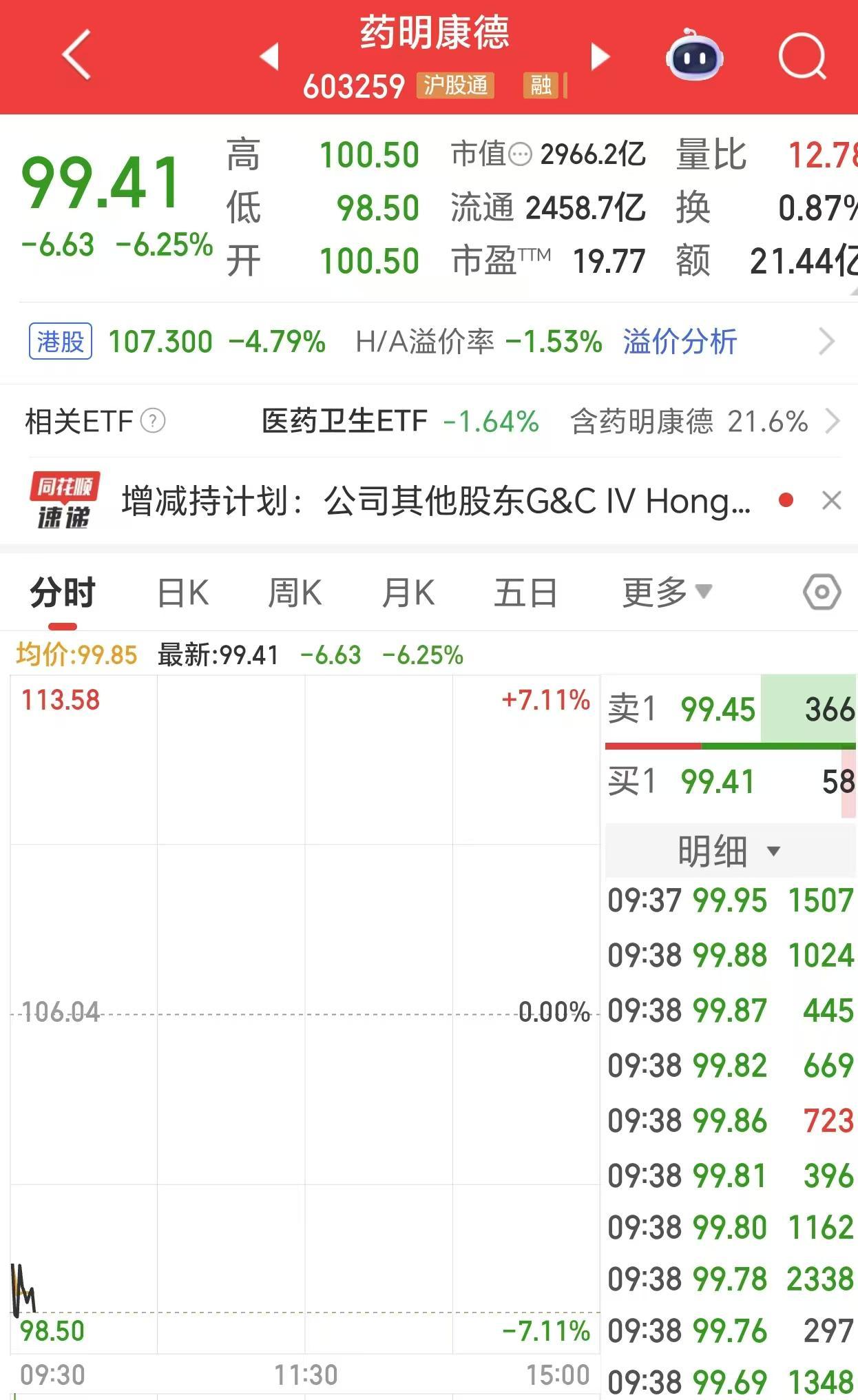
11月18日,全球网络服务巨头Cloudflare突发服务中断,导致包括社交媒体平台X(原Twitter)和人工智能对话工具ChatGPT在内的多个主流互联网平台无法正常访问。尽管Cloudflare在当天晚些时候宣布全面恢复服务,但此次事件再次暴露了全球网络基础设施的脆弱性,引发行业对自动化系统安全风险的深度讨论。
<据Cloudflare官方声明,此次服务中断源于其自动生成的安全配置文件异常。该文件用于管理潜在网络威胁,但因体积过大导致处理流量的核心软件系统崩溃。作为全球网络流量处理量占比达20%的头部服务商,Cloudflare同时承担着保护网站免受流量激增和网络攻击的重要职责。此次故障直接导致其全球范围内的安全防护功能失效,凸显了超大规模网络服务商的系统复杂性风险。
无独有偶,上月亚马逊云服务(AWS)的宕机事件同样造成全球性影响。包括Snapchat、Reddit在内的数千个热门应用陷入瘫痪,故障源头指向亚马逊位于美国北弗吉尼亚数据中心的基础设施故障。该区域作为全球互联网核心枢纽,承载着全球13%和美国四分之一的数据中心算力,其稳定性直接影响全球数字经济的运行。
值得关注的是,两起事件均未发现网络攻击痕迹。Cloudflare明确表示"无证据表明服务中断由恶意活动导致",而AWS故障则被归因于物理基础设施异常。这暴露出当前超大规模网络系统在应对非预期场景时的脆弱性——高度自动化的系统设计虽能提升运营效率,但当遇到预定义规则之外的异常情况时,反而可能成为引发系统性风险的源头。
某网络安全技术总监向第一财经记者分析称:"现代网络基础设施的自动化程度越高,其风险传导速度就越快。当某个节点的配置文件出现异常时,可能通过自动化系统在数秒内扩散至全球网络,这种风险在传统人工运维时代是难以想象的。"
行业专家指出,未来企业部署自动化系统需建立三重防护机制:其一,在技术层面增加异常检测模块;其二,在架构层面设计弹性容错空间;其三,在管理层面制定分级响应预案。特别是对于处理全球流量的核心服务商,必须建立跨地域的冗余备份系统,避免单点故障引发全球性瘫痪。
值得关注的是,在此次Cloudflare全球故障中,中国运营体系展现出独特韧性。公开资料显示,Cloudflare在中国采用与京东云等本土服务商合作的模式,通过本地化数据中心提供服务。这种"技术隔离+生态合作"的策略,使得中国区业务完全独立于全球网络架构,成功规避了国际版服务中断的影响。
有行业观察者预测,随着地缘政治因素和技术主权意识的增强,未来全球互联网将呈现"去中心化"特征。防火墙、主权云和物理隔离带将构成新的网络边界,连接韧性而非单纯速度将成为衡量网络质量的核心指标。这种转变既带来挑战,也为具备本地化运营能力的服务商创造了发展机遇。
微信编辑| 苏小
第一财经持续追踪财经热点。若您掌握公司动态、行业趋势、金融事件等有价值的线索,欢迎提供。专用邮箱:bianjibu@yicai.com
(注:我们会对线索进行核实。您的隐私将严格保密。)