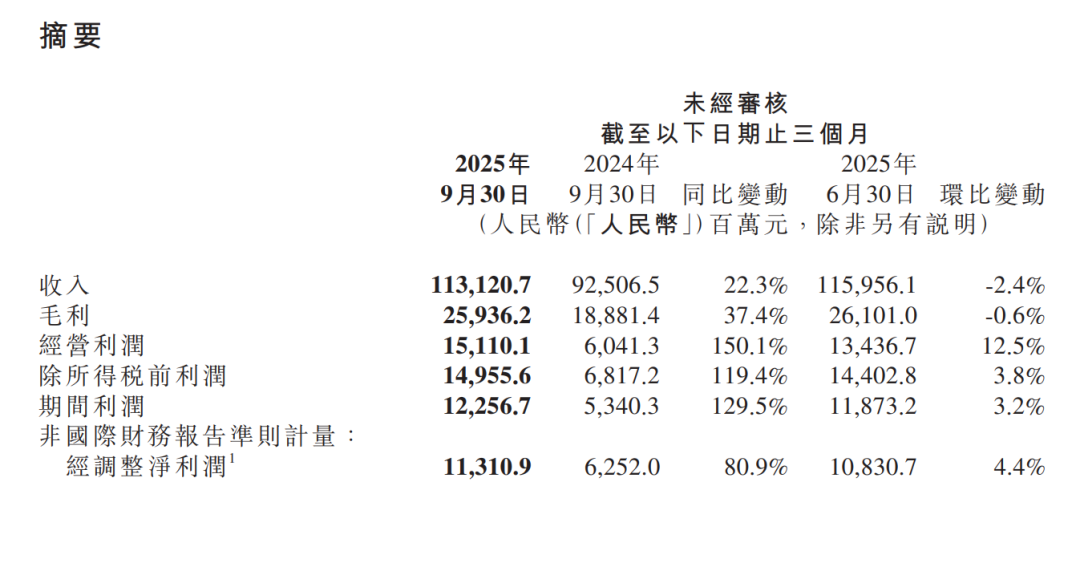
美东时间11月18日早间,全球知名互联网基础设施服务商Cloudflare突发大规模宕机事件,导致依赖其网络与安全服务的众多网站及在线平台出现访问故障。据监测,此次故障影响范围广泛,涵盖社交网络、人工智能服务、电子商务、云服务甚至部分公共交通系统,全球用户普遍遭遇页面加载缓慢、报错提示或完全无法访问的情况。
当天清晨5点20分左右,Cloudflare技术团队首次检测到网络流量异常激增,随后负责处理核心流量的软件系统因错误配置接连崩溃,导致大量请求无法正常响应。根据第三方监测平台DownDetector的数据,X(原Twitter)、Spotify、OpenAI、亚马逊云服务AWS、Shopify、Truth Social等知名服务均出现大面积故障,甚至DownDetector自身也因依赖Cloudflare而短暂中断服务。
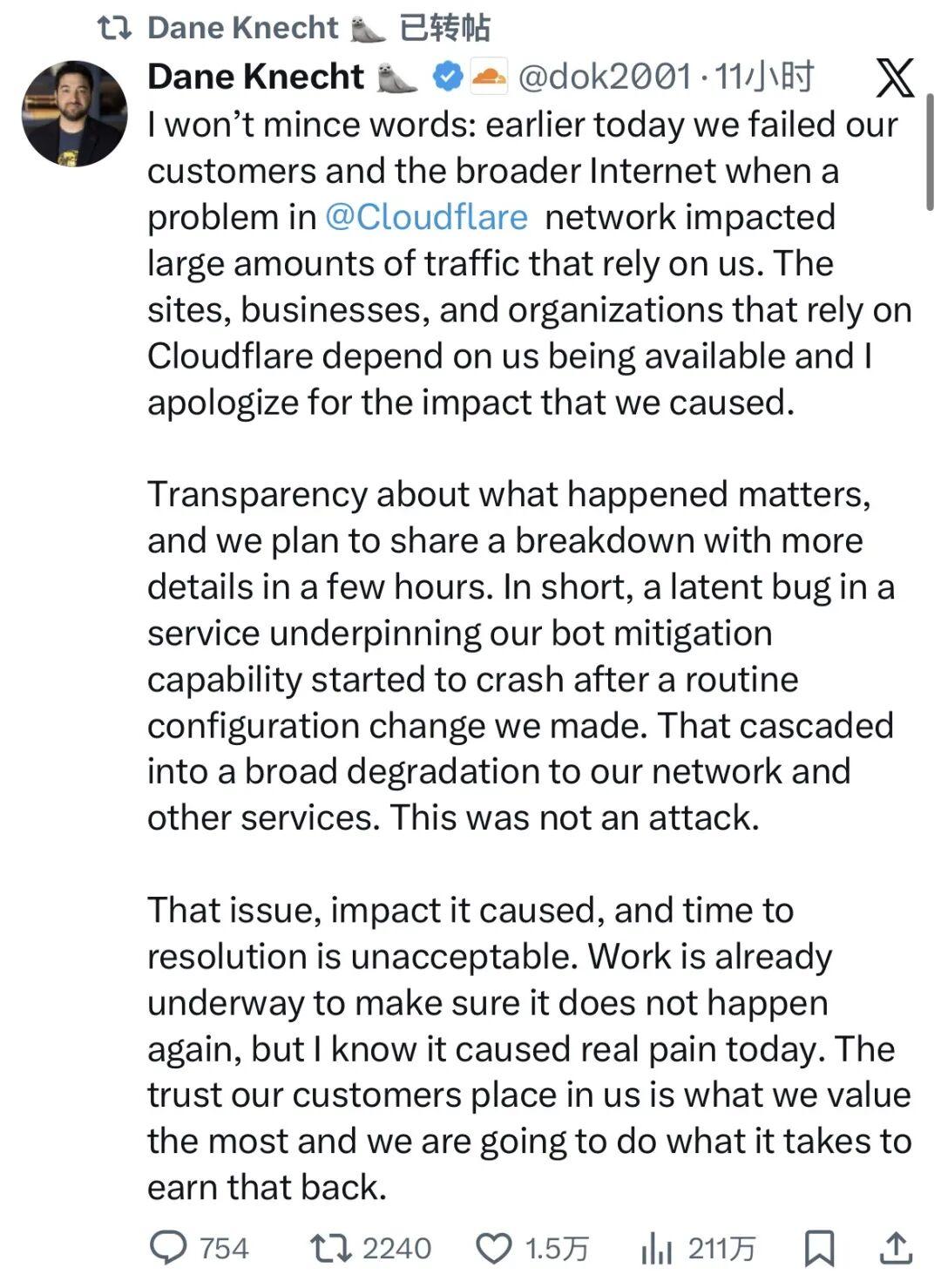
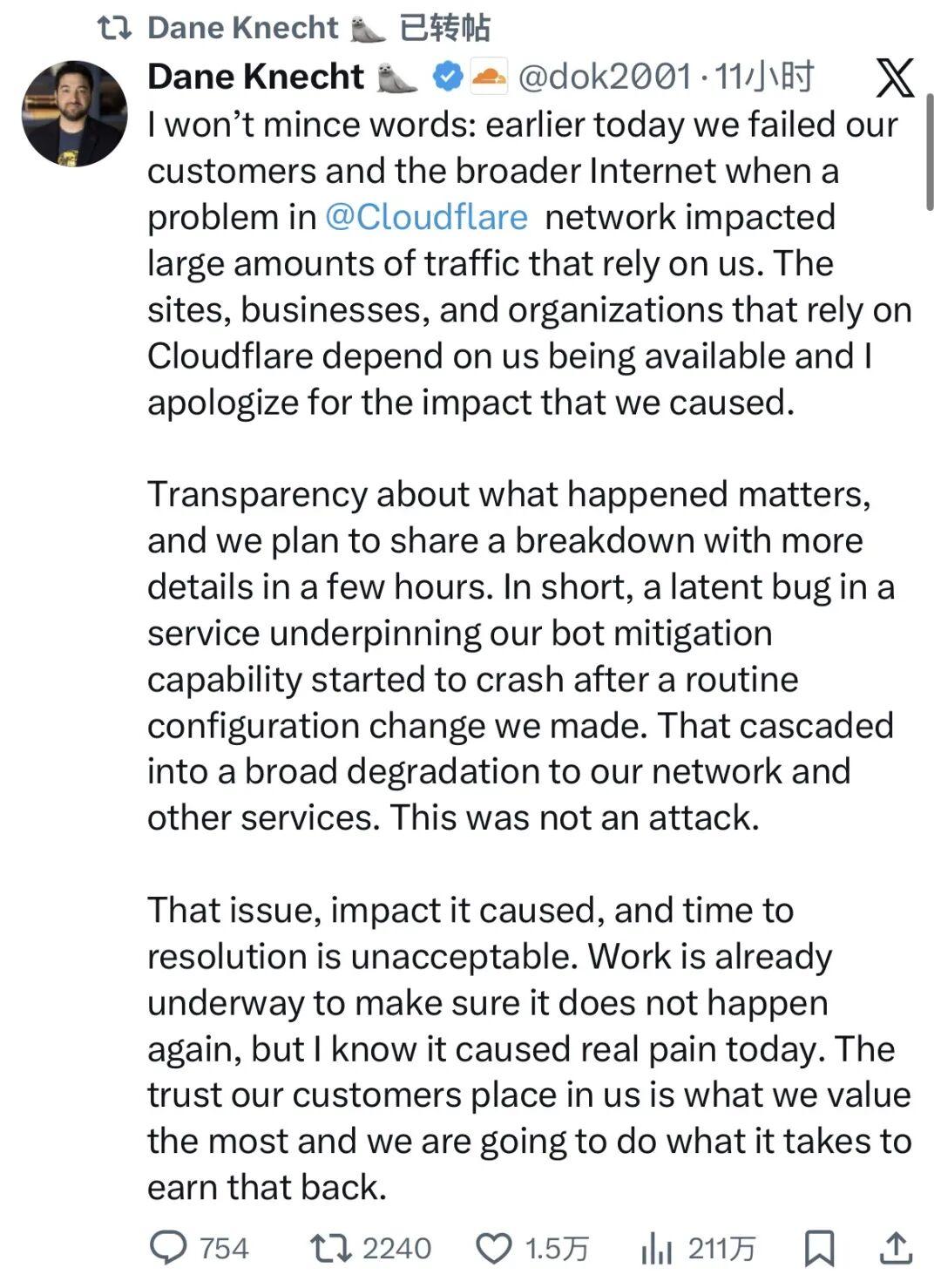
Cloudflare CTO社交媒体发言
故障发生后,Cloudflare迅速启动应急响应。不到两小时内,公司宣布开始调查问题根源;上午7点30分,部分服务逐步恢复,但用户仍可能遇到延迟或错误;8点左右,团队确认故障源头为自动生成配置文件异常升级导致规模失控,触发软件组件崩溃;9点42分至9点57分,Cloudflare发布最新状态更新,宣布核心问题已解决,受影响网站陆续恢复,但管理后台访问仍可能不稳定。
此次事故的根本原因被锁定为Cloudflare内部用于识别和阻断恶意机器人流量的自动生成配置文件。该文件在例行升级后规模意外扩大,远超系统处理能力,最终引发连锁崩溃。Cloudflare首席技术官戴恩·克内希特(Dane Knecht)在社交媒体公开致歉,承认公司“辜负了客户和整个互联网”,同时强调无证据表明事件源于外部攻击或恶意行为。
作为全球处理约20%互联网流量的关键基础设施提供商,Cloudflare的故障直接冲击市场信心。事件发生后,公司股价短时下跌超过2%,投资者对互联网服务集中化风险担忧加剧。Cloudflare承诺将持续监控修复进展,并优化系统以防止类似问题重演。
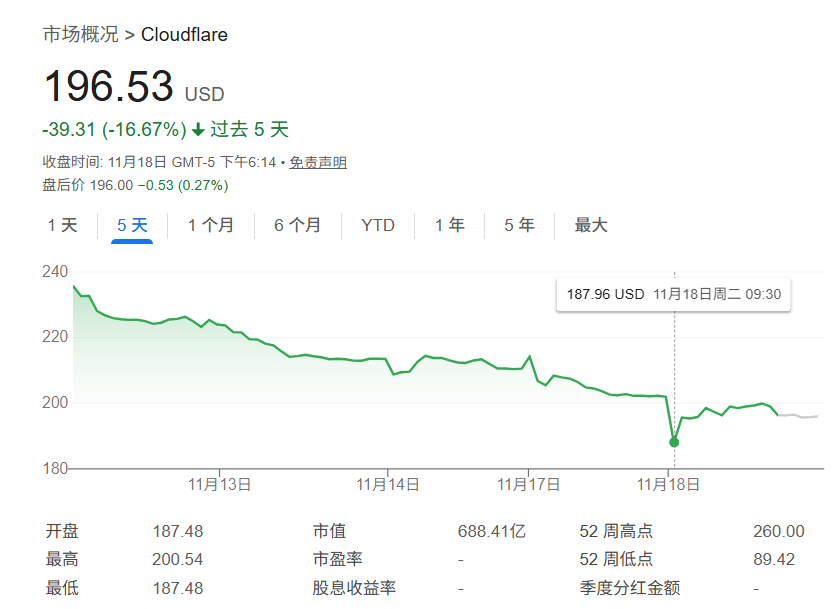
Cloudflare股价波动
网络连接监测组织NetBlocks总监Alp Toker指出,此次事件暴露了互联网基础设施过度集中化的系统性风险。近年来,为提升安全性与稳定性,大量网站将流量托管或保护交由Cloudflare等少数服务商,但这种依赖也使其成为“最大的单点故障之一”。ESET全球网络安全顾问杰克·摩尔(Jake Moore)进一步强调,企业可选择的托管平台有限,过度集中于Cloudflare、AWS或微软等巨头,意味着任何重大故障都可能引发连锁反应。
政府部门亦密切关注事件进展。纽约市应急管理部门表示,已持续监测公共服务运行情况,目前未发现重大资源调度压力。受影响的企业中,OpenAI、Spotify、Shopify、Canva、Zoom及部分公共交通服务均确认因“第三方服务问题”中断,并陆续恢复。
此次宕机并非孤立事件。近一个月内,亚马逊AWS、微软Azure及365服务均曾发生全球性故障,而今年7月美国网络安全服务提供商CrowdStrike的软件升级错误更导致全球范围蓝屏事故,机场停航、银行受阻、医院手术延期,影响持续多日。这些案例凸显了互联网基础设施集中化背后的脆弱性,也为行业敲响警钟。