在科技领域持续升温的GPU竞争中,NVIDIA与AMD正围绕下一代AI架构展开激烈角逐。两家行业巨头通过持续优化设计参数,试图在功耗控制、内存带宽和工艺节点利用率等核心领域建立技术优势。
来源:内容编译自wccftech
AI产品升级战全面打响
根据行业报告及SemiAnalysis的最新分析,AMD Instinct MI450 AI系列与NVIDIA Vera Rubin架构的竞争强度将远超前代产品。双方在多个技术维度实施大规模升级:
高管表态揭示技术路线
AMD服务器业务负责人Forrest Norrod公开表示,Instinct MI450产品线将成为公司的"米兰时刻"(类比EPYC 7003系列服务器的市场突破)。他特别强调:"MI450在综合性能上将超越NVIDIA Vera Rubin,下一代产品将全面采用AMD技术栈。"这种技术自信源于AMD在芯片架构和互联技术上的重大突破。

技术参数持续迭代
SemiAnalysis指出,双方在产品开发过程中多次调整关键参数。以Rubin架构为例,其内存带宽从初期的13TB/s提升至20TB/s,这种提升直接响应了AI计算对高带宽的迫切需求。AMD MI450X通过增加200W功耗预算,在性能释放上获得更大空间。

互联技术革命性突破
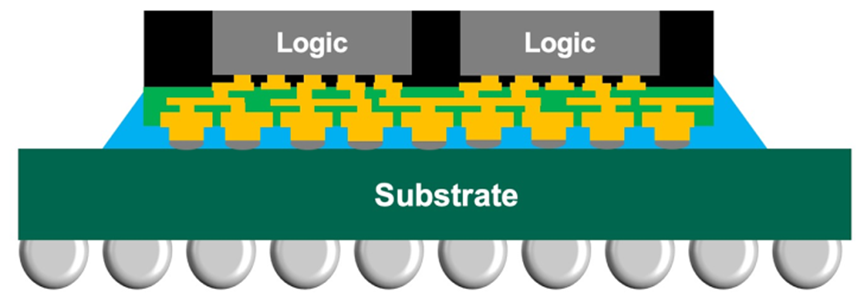
在芯片互联领域,AMD正通过Strix Halo APU验证新一代D2D(芯片到芯片)技术。这项基于台积电InFO-oS(基板集成扇出)和重分布层(RDL)的技术,实现了三大突破:

技术实现层面,AMD在芯片下方中介层布置短距离并行线路,通过InFO-oS技术实现硅芯片与有机基板的直接互联。这种设计移除了传统的大尺寸SERDES模块,转而采用微小焊盘组成的矩形区域,显著降低了功耗和延迟。

市场格局深度重构
随着双方技术差距逐步缩小,GPU市场正进入新的竞争阶段。AMD凭借Zen 6架构的D2D技术突破,在芯片级互联效率上建立优势;NVIDIA则通过持续升级的Rubin架构,在内存带宽和计算密度上保持领先。这场技术竞赛不仅将重塑AI计算的市场格局,更会推动整个半导体行业的技术演进。
免责声明:本文内容基于公开资料整理,观点不代表本平台立场。半导体行业观察转载本文旨在提供多元信息视角,如有异议请联系我们。
关注《半导体行业观察》,获取第4179期深度内容,加星标⭐️不错过任何技术动态