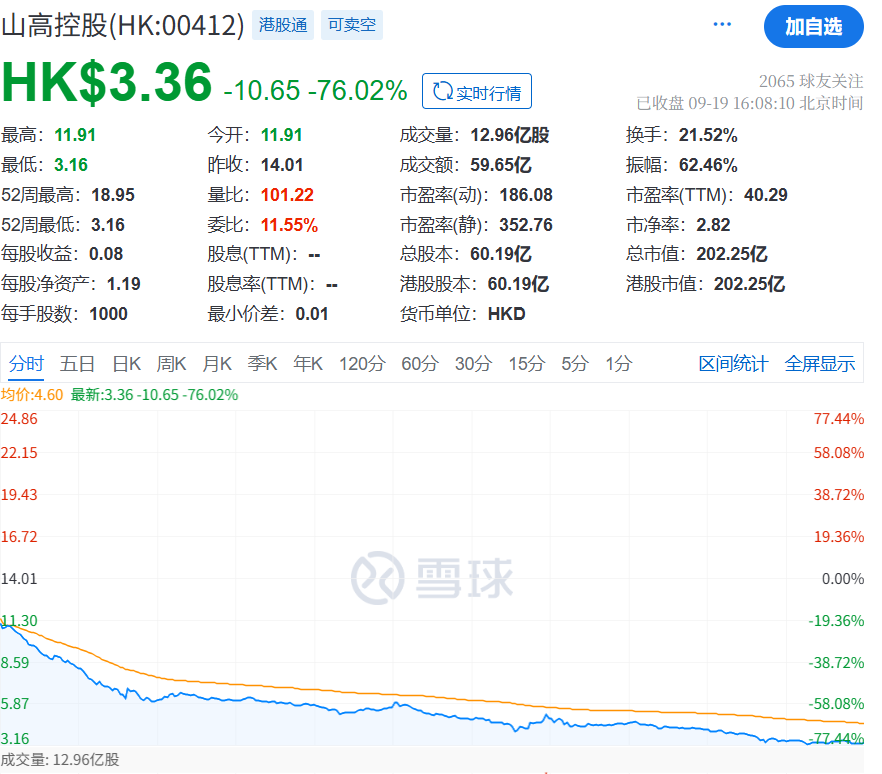
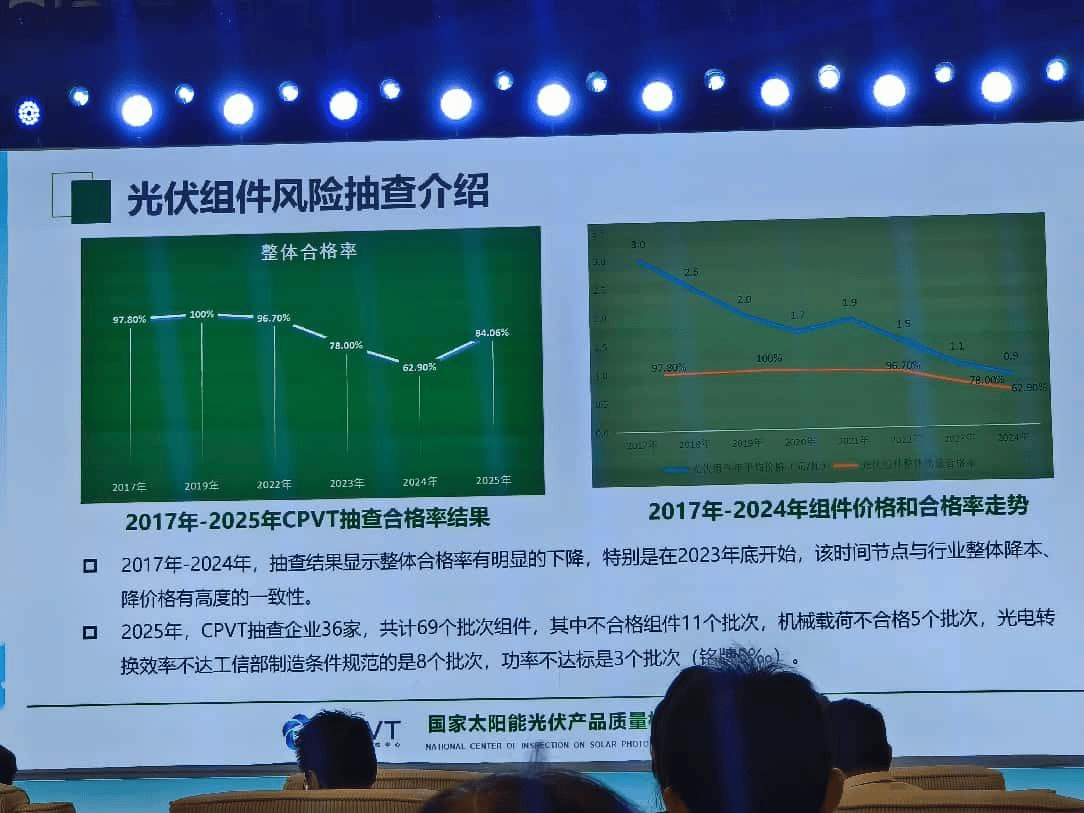
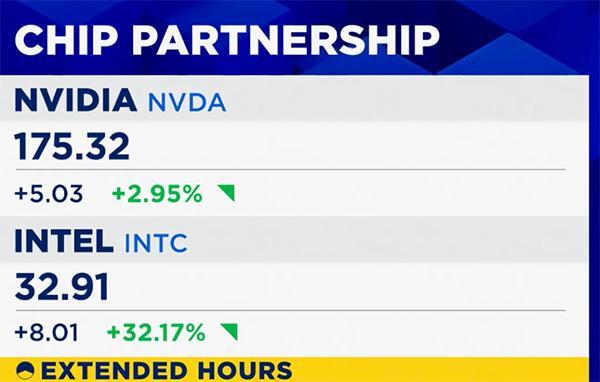
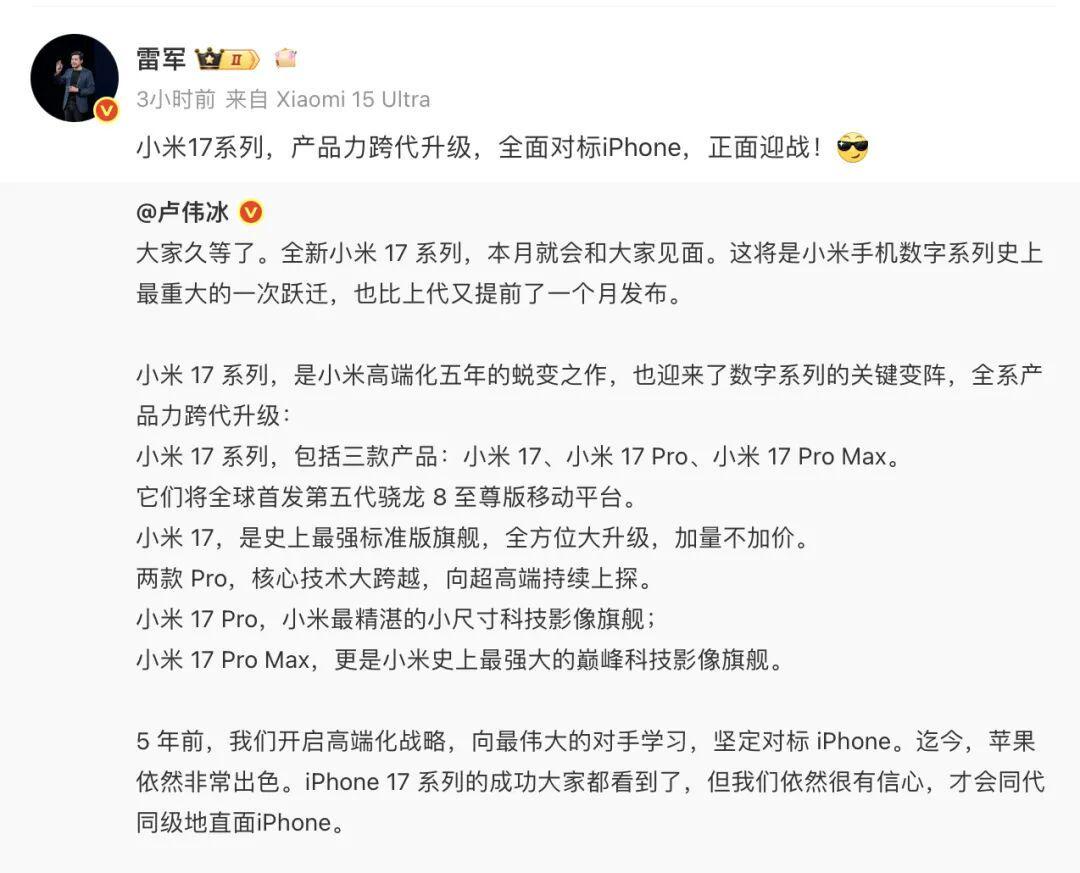
2025年9月29日,人工智能领域迎来重要里程碑——DeepSeek-V3.2-Exp模型正式发布并全面开源。该模型通过引入创新的稀疏Attention架构,在降低计算资源消耗的同时,显著提升了模型推理效率,为大规模AI应用提供了更高效的解决方案。
据官方信息,DeepSeek-V3.2-Exp模型的核心突破在于其稀疏Attention架构设计。这种架构通过动态筛选关键注意力权重,避免了传统全量Attention计算中的冗余操作,从而在保持模型性能的前提下,大幅减少了计算量和内存占用。实验数据显示,该架构可使推理效率提升最高达40%,同时降低30%以上的GPU资源消耗。
目前,DeepSeek-V3.2-Exp模型已正式上架华为云大模型即服务平台(MaaS)。华为云针对该模型特性,延续了大EP并行方案部署策略,并基于稀疏Attention结构创新性地实现了长序列亲和的上下文并行策略。这一部署方案不仅优化了模型时延,还兼顾了吞吐性能,确保在复杂场景下仍能保持稳定高效的运行表现。
行业专家指出,DeepSeek-V3.2-Exp模型的开源将推动AI技术向更高效、更经济的方向发展。其稀疏Attention架构设计为长文本处理、实时推理等场景提供了新的技术路径,有望在金融、医疗、科研等领域引发新一轮应用创新。
此次开源不仅包含模型代码和权重文件,还提供了详细的部署指南和技术文档,方便开发者快速集成和使用。随着模型的广泛应用,预计将加速AI技术在各行业的落地进程,为数字化转型注入新动能。