美东时间11月18日早间,全球互联网基础设施领域发生一起重大事件:知名服务商Cloudflare遭遇大规模宕机,导致依赖其网络与安全服务的众多网站集体受挫。此次故障引发全球范围内多行业网站访问异常,包括社交网络、人工智能服务、电子商务平台、云服务提供商乃至部分公共交通系统均出现访问速度下降、页面报错甚至完全无法访问的情况。
据监测数据显示,当天清晨5点20分左右,Cloudflare系统首先检测到网络流量出现异常激增。随后,负责处理海量服务请求的核心软件组件接连出现错误,导致大量网络请求无法得到正常响应。第三方监测平台DownDetector的实时数据直观展现了此次故障的波及范围:X(原Twitter)、Spotify、OpenAI、亚马逊云服务AWS、Shopify、Truth Social等全球知名互联网服务均出现大面积访问故障,甚至DownDetector自身也因依赖Cloudflare服务而短暂中断访问。
故障发生后,Cloudflare迅速启动应急响应机制。不到两小时,即上午7点30分左右,公司通过官方渠道发布声明称部分服务正在逐步恢复,但用户仍可能遇到访问延迟或错误提示。进入上午8点,技术团队确认已定位故障源头,修复工作全面推进。9点42分至9点57分期间,Cloudflare连续发布状态更新,宣布核心问题已得到解决,大量受影响网站陆续恢复正常访问,不过部分用户访问管理后台时仍可能遭遇不稳定状况。
经技术团队深入排查,本次事故的根本原因指向Cloudflare内部一套用于识别和阻断恶意机器人流量的自动生成配置文件。该配置文件在例行升级过程中规模意外扩大,远超系统设计承载能力,最终触发负责整体流量处理的软件组件持续崩溃,形成连锁反应。
Cloudflare首席技术官戴恩·克内希特(Dane Knecht)通过社交媒体平台X公开致歉:“今天早些时候,Cloudflare网络出现严重问题,影响了大量依赖我们服务的流量,我们辜负了客户和整个互联网社区的信任。”他同时强调,现有证据表明此次事件并非由外部攻击或恶意行为引发。
Cloudflare CTO社交媒体公开致歉
作为全球处理约20%互联网流量的核心基础设施提供商,Cloudflare的此次故障在资本市场引发连锁反应。事件发生后,公司股价在短时间内下跌超过2%,市场情绪受到明显波动。对此,Cloudflare方面表示将持续监控系统修复情况,并承诺采取技术措施避免类似问题再次发生。
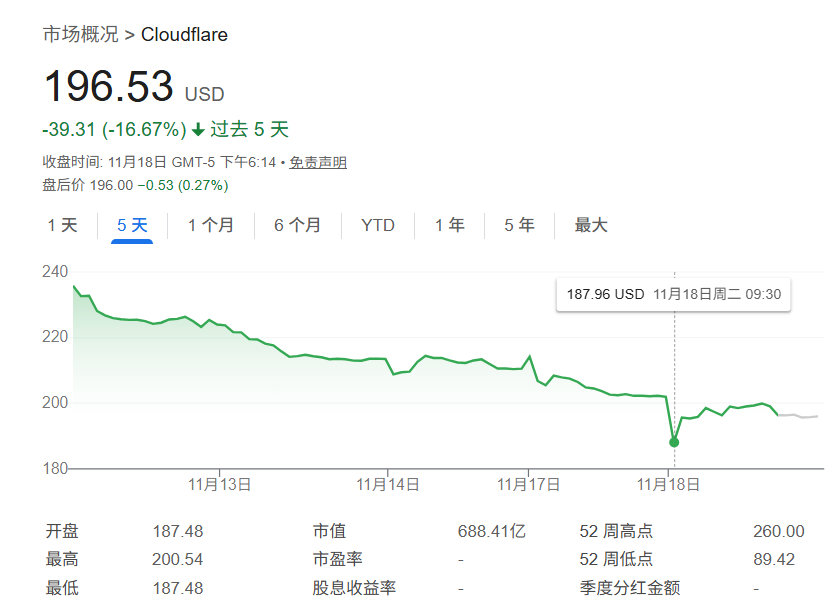
Cloudflare股价波动示意图
网络连接监测组织NetBlocks总监Alp Toker分析指出,本次事件充分暴露了Cloudflare基础设施在遭遇灾难性故障时对全球互联网产生的系统性冲击。近年来,为提升安全防护水平与系统稳定性,越来越多网站选择将流量托管或保护服务交由Cloudflare等少数服务商,这种集中化趋势使其成为互联网“最大的单点故障风险源之一”。
ESET全球网络安全顾问杰克·摩尔(Jake Moore)进一步补充称,由于可信赖的托管平台选择有限,大量企业不得不严重依赖Cloudflare、AWS或微软等大型服务商。这种高度集中的服务架构意味着任何一次重大故障都可能引发跨行业、跨区域的连锁反应,其影响范围往往超出预期。
此次宕机事件的影响范围不仅限于商业领域,政府部门也保持高度关注。纽约市应急管理部门表示,已持续监测该事件对公共服务运行的影响,目前尚未发现对重大资源调度造成实质性压力。截至发稿时,OpenAI、Spotify、Shopify、Canva、Zoom以及部分公共交通服务均已确认因“第三方服务问题”受到不同程度影响,但均已启动恢复程序。
值得关注的是,这已是全球互联网基础服务领域近期发生的又一起大规模事故。就在一个月前,亚马逊AWS出现持续故障,导致超过一千个网站和在线应用瘫痪数小时;微软Azure及365服务也曾发生全球性宕机;今年7月,美国网络安全服务提供商CrowdStrike的一次软件升级错误更引发全球范围蓝屏事故,造成机场停航、银行系统受阻、医院手术延期等严重后果,影响持续多日。这些事件不断警示着互联网基础设施的脆弱性与集中化风险。