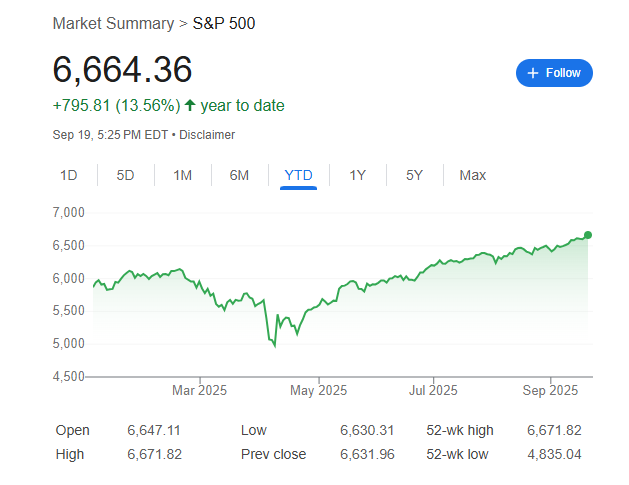
《科创板日报》10月4日讯 当人工智能进入万亿参数时代,传统单卡算力提升模式遭遇瓶颈,一场围绕系统效率的算力革命正在兴起。华为、阿里等国内科技巨头通过'超节点'架构重构AI基础设施,在集群化、高速互联等维度实现技术突破,为国产AI算力基建开辟新赛道。

超节点(Superpod)技术由英伟达率先提出,其核心是将数千张GPU通过高速互联技术集成于单一逻辑单元,形成具备超级计算能力的节点系统。与传统服务器集群相比,超节点通过定制化网络拓扑和低时延通信协议,有效解决了跨节点带宽不足和延迟累积问题,使算力效率获得指数级提升。
这种架构优势在2025云栖大会上得到充分验证。阿里云发布的磐久128超节点AI服务器,集成自研CIPU 2.0芯片与EIC/MOC高性能网卡,单柜支持128个AI计算芯片。实测数据显示,在同等算力条件下,该架构推理性能较传统方案提升50%,验证了超节点在商业场景中的可行性。
头部厂商加速布局:从训练到推理的全场景覆盖
华为在AI训练领域展现出更强技术野心。其CloudMatrix 384超节点通过万卡级集群构建,支持432个超节点级联形成16万卡超大集群,专门针对十万亿参数大模型训练优化。据华为全连接大会披露,该产品已交付300余套,服务20余家政企客户,印证了市场对系统级算力解决方案的迫切需求。
更值得关注的是华为的技术迭代路线:计划2026年四季度推出的Atlas 950 SuperPoD将实现8192卡算力规模,2027年四季度上市的Atlas 960 SuperPoD更将突破15488卡。这种持续升级能力,凸显中国厂商在超节点领域的长期投入决心。
产业生态全面崛起:开源生态+工程化交付成制胜关键
华龙证券分析指出,中美AI竞争正从'单卡性能'转向'系统级效率'维度。中国厂商通过'集群建设+开源生态+工程化交付'的组合策略,在AI基建领域实现弯道超车。这种转变在硬件层面体现得尤为明显:
8月7日,浪潮信息发布面向万亿参数大模型的元脑SD200超节点服务器
沐曦股份推出光互连超节点、耀龙3D Mesh超节点等多元化形态
8月28日,百度智能云百舸AI计算平台5.0启用昆仑芯超节点
民生证券观察到,伴随Scale up产业趋势崛起,超节点正在重新定义AI基础设施范式。以华为Atlas 950为例,其采用全光互联柜间设计,实现零线缆电互联的正交架构,光模块液冷可靠性提升1倍。与英伟达即将推出的NVL144相比,Atlas950在算力规模(56.8倍)、总算力(6.7倍)、内存容量(15倍)、互联带宽(62倍)等核心指标上全面领先。
技术挑战与产业机遇并存
超节点规模化部署带来新的工程挑战。由于单机柜功耗普遍突破100KW,温控和电源系统成为关键瓶颈。华为Atlas950采用全液冷模式后,不仅使互联带宽和算力速率大幅提升,更验证了液冷技术在超密度算力场景中的必要性。
从投资视角看,国金证券认为华为等厂商的新平台在算力、带宽、内存等关键指标上的全面领先,将推动国产算力基础设施加速落地。随着超节点渗透率持续提升,光连接、液冷等供应链环节有望迎来爆发式增长。
这场由超节点引发的算力革命,正在重塑全球AI竞争格局。当行业从'算力堆砌'转向'效率革命',中国厂商凭借系统级创新能力,或将在下一代AI基础设施领域占据先机。