纵观全球科技史,能够通过自我革命摆脱增长困境、重返巅峰的企业屈指可数。20世纪90年代,IBM凭借“大象跳舞”战略完成转型;2014年后,微软通过云服务重塑业务版图。如今,类似的故事正在中国上演——主角是阿里巴巴。
资本市场的反应最为直接。经历长期调整后,阿里股价近期创下2021年8月以来新高。这一轮上涨背后,是市场对其AI战略价值的重新评估:从超预期的云业务财报,到通义大模型的高频迭代,再到自研AI芯片的最新进展,一系列信号正支撑起新的估值逻辑。
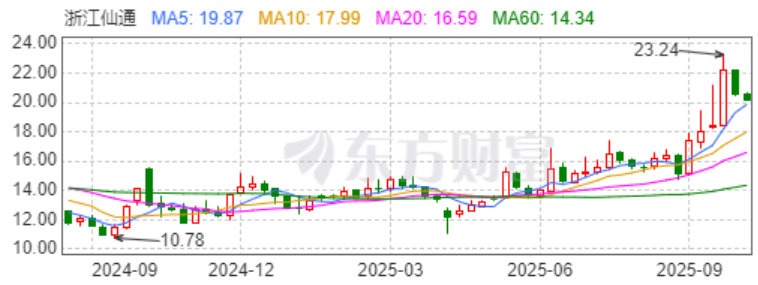
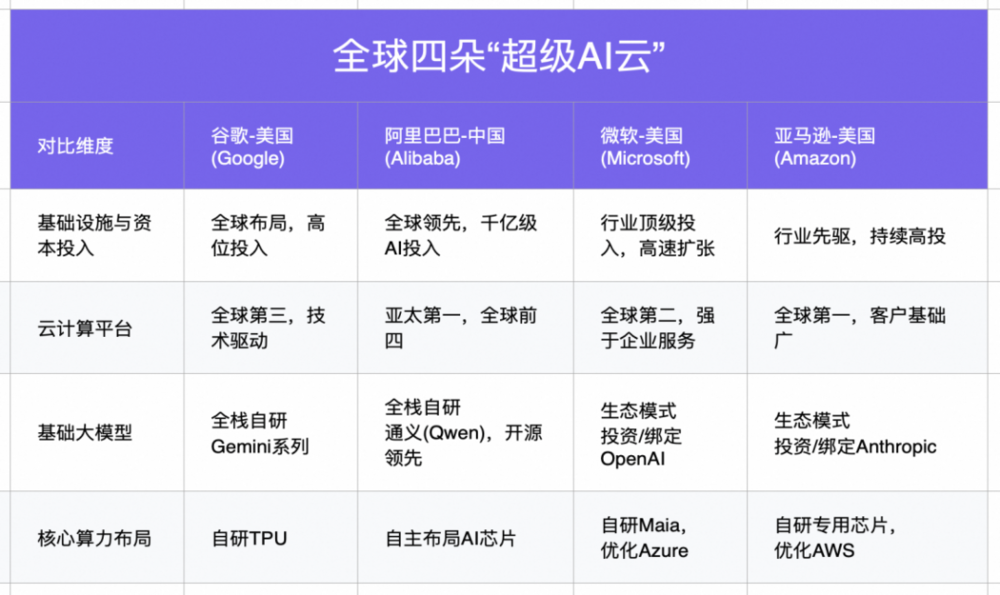
但市场尚未充分认知一个核心事实:阿里巴巴不仅是全球四朵“超级AI云”中唯一的中国公司,更是少数采取“全栈自研”路径的企业——在AI芯片、云计算平台和基础大模型三个核心层面均追求顶尖自研能力,与谷歌形成战略呼应。
ChatGPT引爆的AGI浪潮,初期被误解为“模型竞赛”。2023年“百模大战”的喧嚣背后,一个残酷现实逐渐浮现:模型能力正在快速“平台化”。Transformer架构的公开与高质量开源模型的普及,将顶尖AI能力从少数公司的专利转变为普惠基础设施。加上顶级玩家在算力上的饱和投入,各家模型的能力差距迅速缩小。
这场竞赛的终局形态,并非决出最聪明的单一模型,而是看谁能构建起最强大的AI全栈技术体系——一套集模型、云平台、芯片、生态于一体,并能协同演进的系统性能力。
决定AI竞赛胜负的,不是某一刻的领先,而是迭代速度和成本效率。要同时优化这两个变量,企业必须构建垂直整合的AI全栈技术体系。这一体系由四个相互关联的要素构成:
第一,千亿级资本投入。这是构建大规模AI基础设施、招募顶尖人才并支撑长期研发的必要前提。
第二,百万级集群的云计算能力。这是为大规模并行训练提供计算环境的关键,直接决定模型迭代速度上限。
第三,世界级基础大模型。这是软硬件协同优化的核心对象,连接上层应用与底层算力的关键环节。
第四,自主AI芯片布局。这是实现成本控制的关键手段,通过为自研模型定制硬件,降低推理成本。
谷歌的案例印证了这一体系的有效性。ChatGPT发布后,谷歌曾一度被动。但当其发布Gemini系列模型时,外界发现其快速追平了领先者。这场追赶的实现,并非仅靠模型算法突破,而是其完整全栈能力协同作用的结果。
首先,全栈体系决定了模型迭代速度。AI技术栈耦合程度极高,非全栈体系中,软硬件协同瓶颈的定位和解决周期可能长达数周。而在全栈自研公司中,谷歌的AI科学家可以与TPU硬件团队和数据中心网络工程师紧密协作,将技术反馈闭环速度提升到极致,从而加速Gemini的追赶进程。
其次,全栈体系从根本上决定了成本效率。AI成本分为训练成本和更为庞大的推理成本。非全栈玩家面临“多重溢价”,需向芯片、云平台等供应商支付利润。而拥有自主硬件能力的全栈玩家,可以通过“软硬件协同设计”优化成本结构。正如OpenAI CEO萨姆·奥尔特曼所言,谁能将推理成本降到足够低,谁就能在商业化中占据主动。
以“超级AI云”四个标准扫描全球科技版图,结果清晰:在美国,谷歌、微软和亚马逊均已完成关键布局;在中国,阿里巴巴是唯一完全符合定义的公司。
在全球IaaS市场,亚马逊AWS、微软Azure、阿里云和谷歌云构成合计份额近80%的第一梯队。阿里云作为其中唯一的中国公司,其规模与技术积累是参与全球竞赛的先决条件。
同时,阿里通过将通义Qwen系列大模型大规模开源,形成全球最大的AI开发者生态;另一方面则在核心算力上自主布局,实现硬件与模型的深度协同,构筑长期成本优势。这种“模型开源吸引生态,硬件自研控制成本”的策略,与谷歌形成跨洋呼应。
支撑这一切的是史无前例的激进投入。早在今年2月,阿里就宣布未来三年投入3800亿元用于建设云和AI基础设施,超过去十年总和。其CEO吴泳铭在2026财年第一季度财报会上透露,过去四个季度已在AI基础设施及AI产品研发上累计投入超过1000亿元。
至此,全球“超级AI云”的牌桌格局已经形成:美国三家,中国一家。这四家公司,正在成为定义下一代技术基础设施的核心力量,并深远地影响未来的全球产业格局。
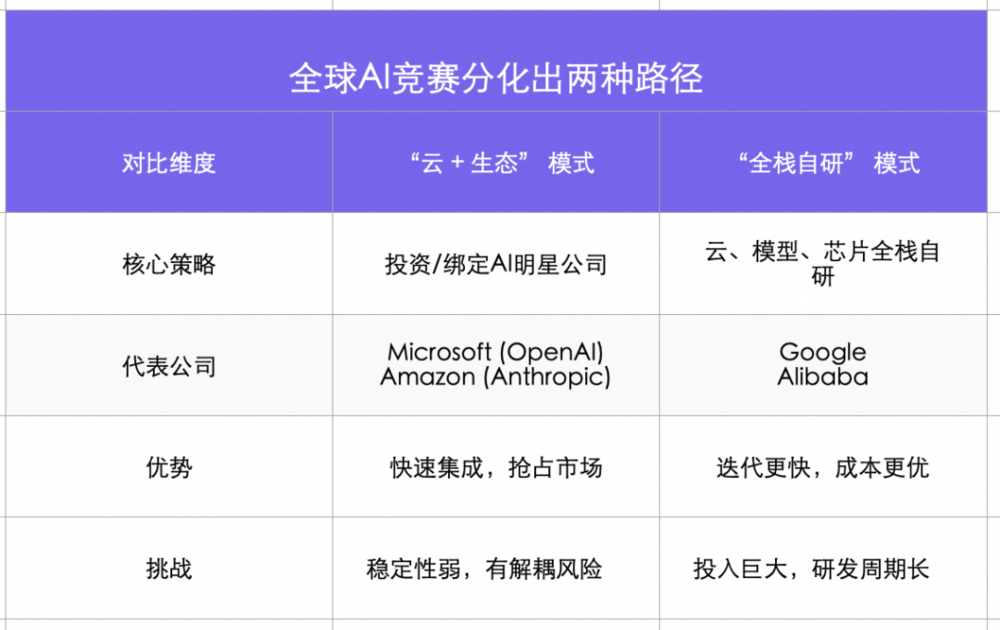
拿到“超级AI云”入场券后,四家公司的战略路径出现明显分化,主要体现在如何解决“模型”这一核心环节上,并由此形成了两种不同的模式。
微软和亚马逊代表的“云+生态”模式,核心是通过巨额资本注入和深度业务绑定,与市场上最顶尖的AI创业公司形成战略同盟。微软选择了OpenAI,亚马逊则向Anthropic注资。此举能快速将最先进的AI能力打包提供给其庞大的企业客户群,在商业化初期抢占市场。
但这种模式的协同效率和战略稳定性也面临挑战。为避免科技巨头过度干预,OpenAI和Anthropic都采取了特殊的治理架构,微软和亚马逊均无董事会席位和投票权。这种法律上的“防火墙”意味着同盟关系并非绝对绑定。2025年以来,有信息显示OpenAI正与甲骨文(Oracle)和软银接触,寻求新的算力和资本支持,以降低对单一伙伴的依赖。
与此相对,谷歌和阿里巴巴选择了第二条路——“全栈自研”。这一模式的价值,在苹果公司身上得到了验证:它通过自研M系列芯片、macOS系统和Mac硬件的全栈整合,实现了出色的性能和体验。如今,谷歌和阿里正将这一范式应用到AI云领域,通过对AI芯片、云计算平台和基础大模型三个核心层面的端到端自研,实现“软硬件协同设计”。
这条路径更考验综合实力和长期投入,但对整个技术栈的端到端控制力,意味着能实现更快的创新迭代和更优的成本结构。这种深度的技术整合,正在转化为业绩增长。
最新的财报季,这一趋势尤为明显。谷歌云业务收入增速从28%加速至32%,而阿里云收入增速也从18%大幅攀升至26%。两家公司业绩的强劲增长,都与其全栈AI能力的释放直接相关。
巨额投入正迅速转化为技术成果。7月以来,阿里接连发布并开源了Qwen3推理模型、Qwen3-Coder编程模型等多个重量级模型。目前,通义千问Qwen衍生模型数量已突破17万,超越美国Llama模型,通义成为全球第一AI开源模型。
在AI这场终将回归成本和效率的持久战中,对整个技术栈拥有端到端控制力的“全栈玩家”,在战略后劲和成本结构上拥有更清晰的优势。
2025年8月,长期坚持闭源路线的OpenAI做出了一个重大的战略调整,宣布开源两款核心模型。业内普遍认为,此举是对日益增长的中国开源力量的直接回应。以DeepSeek和阿里通义千问Qwen为代表的中国模型,不仅在技术榜单上表现出色,更通过庞大的开发者生态,开始影响全球AI的技术范式。
开源模型的领先,是中国AI产业在应用和生态层面取得的显著成果。在此基础上,能否将这一成果转化为长期的、系统性的产业优势,则取决于一个更深层的问题:是否具备完整的“全栈AI能力”。
这背后的产业逻辑十分清晰:一个开源模型,相当于一张公开的、先进的设计图纸。但真正的壁垒在于能否拥有将这张图纸大规模、低成本、高效率地转化为成品的完整工业体系。在AI领域,这个“工业体系”就是集自研芯片、大规模云计算平台和基础大模型于一体的垂直整合能力。它直接决定了技术迭代的速度和商业化部署的成本结构。
在云计算时代,阿里云为代表的中国公司,第一次在底层技术设施领域进入全球第一梯队,与亚马逊、微软形成了新的竞争格局。
今天,云计算作为上一个时代的终点,已经成为AI这个新时代的起点。在这块由中美共同主导的基础设施之上,一场围绕“全栈能力”的更深层次的产业竞赛已经开始。
本内容为作者独立观点,不代表虎嗅立场。未经允许不得转载,授权事宜请联系hezuo@huxiu.com
本文来自虎嗅,原文链接:https://www.huxiu.com/article/4782676.html?f=wyxwapp